Representación de Zeckendorf
Los primeros números de Fibonacci son
|
1 |
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, ... |
tales que los dos primeros son iguales a 1 y los siguientes se obtienen sumando los dos anteriores.
El teorema de Zeckendorf establece que todo entero positivo n se puede representar, de manera única, como la suma de números de Fibonacci no consecutivos decrecientes. Dicha suma se llama la representación de Zeckendorf de n. Por ejemplo, la representación de Zeckendorf de 100 es
|
1 |
100 = 89 + 8 + 3 |
Hay otras formas de representar 100 como sumas de números de Fibonacci; por ejemplo,
|
1 2 |
100 = 89 + 8 + 2 + 1 100 = 55 + 34 + 8 + 3 |
pero no son representaciones de Zeckendorf porque 1 y 2 son números de Fibonacci consecutivos, al igual que 34 y 55.
Definir la función
|
1 |
zeckendorf :: Integer -> [Integer] |
tal que (zeckendorf n) es la representación de Zeckendorf de n. Por ejemplo,
|
1 2 3 4 |
zeckendorf 100 == [89,8,3] zeckendorf 200 == [144,55,1] zeckendorf 300 == [233,55,8,3,1] length (zeckendorf (10^50000)) == 66097 |
Soluciones
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
module Representacion_de_Zeckendorf where import Data.List (subsequences) import Test.QuickCheck -- 1ª solución -- =========== zeckendorf1 :: Integer -> [Integer] zeckendorf1 = head . zeckendorf1Aux zeckendorf1Aux :: Integer -> [[Integer]] zeckendorf1Aux n = [xs | xs <- subsequences (reverse (takeWhile (<= n) (tail fibs))), sum xs == n, sinFibonacciConsecutivos xs] -- fibs es la la sucesión de los números de Fibonacci. Por ejemplo, -- take 14 fibs == [1,1,2,3,5,8,13,21,34,55,89,144,233,377] fibs :: [Integer] fibs = 1 : scanl (+) 1 fibs -- (sinFibonacciConsecutivos xs) se verifica si en la sucesión -- decreciente de número de Fibonacci xs no hay dos consecutivos. Por -- ejemplo, -- (sinFibonacciConsecutivos xs) se verifica si en la sucesión -- decreciente de número de Fibonacci xs no hay dos consecutivos. Por -- ejemplo, -- sinFibonacciConsecutivos [89, 8, 3] == True -- sinFibonacciConsecutivos [55, 34, 8, 3] == False sinFibonacciConsecutivos :: [Integer] -> Bool sinFibonacciConsecutivos xs = and [x /= siguienteFibonacci y | (x,y) <- zip xs (tail xs)] -- (siguienteFibonacci n) es el menor número de Fibonacci mayor que -- n. Por ejemplo, -- siguienteFibonacci 34 == 55 siguienteFibonacci :: Integer -> Integer siguienteFibonacci n = head (dropWhile (<= n) fibs) -- 2ª solución -- =========== zeckendorf2 :: Integer -> [Integer] zeckendorf2 = head . zeckendorf2Aux zeckendorf2Aux :: Integer -> [[Integer]] zeckendorf2Aux n = map reverse (aux n (tail fibs)) where aux 0 _ = [[]] aux m (x:y:zs) | x <= m = [x:xs | xs <- aux (m-x) zs] ++ aux m (y:zs) | otherwise = [] -- 3ª solución -- =========== zeckendorf3 :: Integer -> [Integer] zeckendorf3 0 = [] zeckendorf3 n = x : zeckendorf3 (n - x) where x = last (takeWhile (<= n) fibs) -- 4ª solución -- =========== zeckendorf4 :: Integer -> [Integer] zeckendorf4 n = aux n (reverse (takeWhile (<= n) fibs)) where aux 0 _ = [] aux m (x:xs) = x : aux (m-x) (dropWhile (>m-x) xs) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_zeckendorf :: Positive Integer -> Bool prop_zeckendorf (Positive n) = all (== zeckendorf1 n) [zeckendorf2 n, zeckendorf3 n, zeckendorf4 n] -- La comprobación es -- λ> quickCheck prop_zeckendorf -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> zeckendorf1 (7*10^4) -- [46368,17711,4181,1597,89,34,13,5,2] -- (1.49 secs, 2,380,707,744 bytes) -- λ> zeckendorf2 (7*10^4) -- [46368,17711,4181,1597,89,34,13,5,2] -- (0.07 secs, 21,532,008 bytes) -- -- λ> zeckendorf2 (10^6) -- [832040,121393,46368,144,55] -- (1.40 secs, 762,413,432 bytes) -- λ> zeckendorf3 (10^6) -- [832040,121393,46368,144,55] -- (0.01 secs, 542,488 bytes) -- λ> zeckendorf4 (10^6) -- [832040,121393,46368,144,55] -- (0.01 secs, 536,424 bytes) -- -- λ> length (zeckendorf3 (10^3000)) -- 3947 -- (3.02 secs, 1,611,966,408 bytes) -- λ> length (zeckendorf4 (10^2000)) -- 2611 -- (0.02 secs, 10,434,336 bytes) -- -- λ> length (zeckendorf4 (10^50000)) -- 66097 -- (2.84 secs, 3,976,483,760 bytes) |
El código se encuentra en GitHub.
La elaboración de las soluciones se describe en el siguiente vídeo




 , cifra que luego de algunos refinamientos se redujo a
, cifra que luego de algunos refinamientos se redujo a 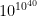 .
.

