import Data.List (nub, sort)
import Data.Array (Array, (!), array, elems, listArray)
-- 1ª solución
-- ===========
longitudMayorSublistaCreciente1 :: Ord a => [a] -> Int
longitudMayorSublistaCreciente1 =
length . head . mayoresCrecientes
-- (mayoresCrecientes xs) es la lista de las sublistas crecientes de xs
-- de mayor longitud. Por ejemplo,
-- λ> mayoresCrecientes [3,2,6,4,5,1]
-- [[3,4,5],[2,4,5]]
-- λ> mayoresCrecientes [3,2,3,2,3,1]
-- [[2,3],[2,3],[2,3]]
-- λ> mayoresCrecientes [10,22,9,33,21,50,41,60,80]
-- [[10,22,33,50,60,80],[10,22,33,41,60,80]]
-- λ> mayoresCrecientes [0,8,4,12,2,10,6,14,1,9,5,13,3,11,7,15]
-- [[0,4,6,9,13,15],[0,2,6,9,13,15],[0,4,6,9,11,15],[0,2,6,9,11,15]]
mayoresCrecientes :: Ord a => [a] -> [[a]]
mayoresCrecientes xs =
[ys | ys <- xss
, length ys == m]
where xss = sublistasCrecientes xs
m = maximum (map length xss)
-- (sublistasCrecientes xs) es la lista de las sublistas crecientes de
-- xs. Por ejemplo,
-- λ> sublistasCrecientes [3,2,5]
-- [[3,5],[3],[2,5],[2],[5],[]]
sublistasCrecientes :: Ord a => [a] -> [[a]]
sublistasCrecientes [] = [[]]
sublistasCrecientes (x:xs) =
[x:ys | ys <- yss, null ys || x < head ys] ++ yss
where yss = sublistasCrecientes xs
-- 2ª solución
-- ===========
longitudMayorSublistaCreciente2 :: Ord a => [a] -> Int
longitudMayorSublistaCreciente2 xs =
longitudSCM xs (sort (nub xs))
-- (longitudSCM xs ys) es la longitud de la subsecuencia máxima de xs e
-- ys. Por ejemplo,
-- longitudSCM "amapola" "matamoscas" == 4
-- longitudSCM "atamos" "matamoscas" == 6
-- longitudSCM "aaa" "bbbb" == 0
longitudSCM :: Eq a => [a] -> [a] -> Int
longitudSCM xs ys = (matrizLongitudSCM xs ys) ! (n,m)
where n = length xs
m = length ys
-- (matrizLongitudSCM xs ys) es la matriz de orden (n+1)x(m+1) (donde n
-- y m son los números de elementos de xs e ys, respectivamente) tal que
-- el valor en la posición (i,j) es la longitud de la SCM de los i
-- primeros elementos de xs y los j primeros elementos de ys. Por ejemplo,
-- λ> elems (matrizLongitudSCM "amapola" "matamoscas")
-- [0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,1,1,1,1,2,2,2,2,2,2,
-- 0,1,2,2,2,2,2,2,2,3,3,0,1,2,2,2,2,2,2,2,3,3,0,1,2,2,2,2,3,3,3,3,3,
-- 0,1,2,2,2,2,3,3,3,3,3,0,1,2,2,3,3,3,3,3,4,4]
-- Gráficamente,
-- m a t a m o s c a s
-- [0,0,0,0,0,0,0,0,0,0,0,
-- a 0,0,1,1,1,1,1,1,1,1,1,
-- m 0,1,1,1,1,2,2,2,2,2,2,
-- a 0,1,2,2,2,2,2,2,2,3,3,
-- p 0,1,2,2,2,2,2,2,2,3,3,
-- o 0,1,2,2,2,2,3,3,3,3,3,
-- l 0,1,2,2,2,2,3,3,3,3,3,
-- a 0,1,2,2,3,3,3,3,3,4,4]
matrizLongitudSCM :: Eq a => [a] -> [a] -> Array (Int,Int) Int
matrizLongitudSCM xs ys = q
where
n = length xs
m = length ys
v = listArray (1,n) xs
w = listArray (1,m) ys
q = array ((0,0),(n,m)) [((i,j), f i j) | i <- [0..n], j <- [0..m]]
where f 0 _ = 0
f _ 0 = 0
f i j | v ! i == w ! j = 1 + q ! (i-1,j-1)
| otherwise = max (q ! (i-1,j)) (q ! (i,j-1))
-- 3ª solución
-- ===========
longitudMayorSublistaCreciente3 :: Ord a => [a] -> Int
longitudMayorSublistaCreciente3 xs =
maximum (elems (vectorlongitudMayorSublistaCreciente xs))
-- (vectorlongitudMayorSublistaCreciente xs) es el vector de longitud n
-- (donde n es el tamaño de xs) tal que el valor i-ésimo es la longitud
-- de la sucesión más larga que termina en el elemento i-ésimo de
-- xs. Por ejemplo,
-- λ> vectorlongitudMayorSublistaCreciente [3,2,6,4,5,1]
-- array (1,6) [(1,1),(2,1),(3,2),(4,2),(5,3),(6,1)]
vectorlongitudMayorSublistaCreciente :: Ord a => [a] -> Array Int Int
vectorlongitudMayorSublistaCreciente xs = v
where v = array (1,n) [(i,f i) | i <- [1..n]]
n = length xs
w = listArray (1,n) xs
f 1 = 1
f i | null ls = 1
| otherwise = 1 + maximum ls
where ls = [v ! j | j <-[1..i-1], w ! j < w ! i]
-- Comparación de eficiencia
-- =========================
-- λ> longitudMayorSublistaCreciente1 [1..20]
-- 20
-- (4.60 secs, 597,014,240 bytes)
-- λ> longitudMayorSublistaCreciente2 [1..20]
-- 20
-- (0.03 secs, 361,384 bytes)
-- λ> longitudMayorSublistaCreciente3 [1..20]
-- 20
-- (0.03 secs, 253,944 bytes)
--
-- λ> longitudMayorSublistaCreciente2 [1..2000]
-- 2000
-- (8.00 secs, 1,796,495,488 bytes)
-- λ> longitudMayorSublistaCreciente3 [1..2000]
-- 2000
-- (5.12 secs, 1,137,667,496 bytes)
--
-- λ> longitudMayorSublistaCreciente1 [1000,999..1]
-- 1
-- (0.95 secs, 97,029,328 bytes)
-- λ> longitudMayorSublistaCreciente2 [1000,999..1]
-- 1
-- (7.48 secs, 1,540,857,208 bytes)
-- λ> longitudMayorSublistaCreciente3 [1000,999..1]
-- 1
-- (0.86 secs, 160,859,128 bytes)
--
-- λ> longitudMayorSublistaCreciente1 (show (2^300))
-- 10
-- (7.90 secs, 887,495,368 bytes)
-- λ> longitudMayorSublistaCreciente2 (show (2^300))
-- 10
-- (0.04 secs, 899,152 bytes)
-- λ> longitudMayorSublistaCreciente3 (show (2^300))
-- 10
-- (0.04 secs, 1,907,936 bytes)
--
-- λ> longitudMayorSublistaCreciente2 (show (2^6000))
-- 10
-- (0.06 secs, 9,950,592 bytes)
-- λ> longitudMayorSublistaCreciente3 (show (2^6000))
-- 10
-- (3.46 secs, 686,929,744 bytes)
--
-- λ> import System.Random
-- (0.00 secs, 0 bytes)
-- λ> xs <- sequence [randomRIO (0,10^6) | _ <- [1..10^3]]
-- (0.02 secs, 1,993,032 bytes)
-- λ> longitudMayorSublistaCreciente2 xs
-- 61
-- (7.73 secs, 1,538,771,392 bytes)
-- λ> longitudMayorSublistaCreciente3 xs
-- 61
-- (1.04 secs, 212,538,648 bytes)
-- λ> xs <- sequence [randomRIO (0,10^6) | _ <- [1..10^3]]
-- (0.03 secs, 1,993,032 bytes)
-- λ> longitudMayorSublistaCreciente2 xs
-- 57
-- (7.56 secs, 1,538,573,680 bytes)
-- λ> longitudMayorSublistaCreciente3 xs
-- 57
-- (1.05 secs, 212,293,984 bytes)
 , cifra que luego de algunos refinamientos se redujo a
, cifra que luego de algunos refinamientos se redujo a 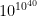 .
.


