Sucesión de sumas de dos números abundantes
Un número n es abundante si la suma de los divisores propios de n es mayor que n. El primer número abundante es el 12 (cuyos divisores propios son 1, 2, 3, 4 y 6 cuya suma es 16). Por tanto, el menor número que es la suma de dos números abundantes es el 24.
Definir la sucesión
|
1 |
sumasDeDosAbundantes :: [Integer] |
cuyos elementos son los números que se pueden escribir como suma de dos números abundantes. Por ejemplo,
|
1 |
take 10 sumasDeDosAbundantes == [24,30,32,36,38,40,42,44,48,50] |
Soluciones
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import Data.List (genericLength, group) import Data.Numbers.Primes (primeFactors) import Test.QuickCheck -- 1ª solución -- =========== sumasDeDosAbundantes1 :: [Integer] sumasDeDosAbundantes1 = [n | n <- [1..], esSumaDeDosAbundantes n] -- (esSumaDeDosAbundantes n) se verifica si n es suma de dos números -- abundantes. Por ejemplo, -- esSumaDeDosAbundantes 24 == True -- any esSumaDeDosAbundantes [1..22] == False esSumaDeDosAbundantes :: Integer -> Bool esSumaDeDosAbundantes n = (not . null) [x | x <- xs, n-x `elem` xs] where xs = takeWhile (<n) abundantes -- abundantes es la lista de los números abundantes. Por ejemplo, -- take 10 abundantes == [12,18,20,24,30,36,40,42,48,54] abundantes :: [Integer] abundantes = [n | n <- [2..], abundante n] -- (abundante n) se verifica si n es abundante. Por ejemplo, -- abundante 12 == True -- abundante 11 == False abundante :: Integer -> Bool abundante n = sum (divisores n) > n -- (divisores n) es la lista de los divisores propios de n. Por ejemplo, -- divisores 12 == [1,2,3,4,6] divisores :: Integer -> [Integer] divisores n = [x | x <- [1..n `div` 2], n `mod` x == 0] -- 2ª solución -- =========== sumasDeDosAbundantes2 :: [Integer] sumasDeDosAbundantes2 = filter esSumaDeDosAbundantes2 [1..] esSumaDeDosAbundantes2 :: Integer -> Bool esSumaDeDosAbundantes2 n = (not . null) [x | x <- xs, n-x `elem` xs] where xs = takeWhile (<n) abundantes2 abundantes2 :: [Integer] abundantes2 = filter abundante2 [2..] abundante2 :: Integer -> Bool abundante2 n = sumaDivisores n > n sumaDivisores :: Integer -> Integer sumaDivisores x = product [(p^(e+1)-1) `div` (p-1) | (p,e) <- factorizacion x] - x -- (factorizacion x) es la lista de las bases y exponentes de la -- descomposición prima de x. Por ejemplo, -- factorizacion 600 == [(2,3),(3,1),(5,2)] factorizacion :: Integer -> [(Integer,Integer)] factorizacion = map primeroYlongitud . group . primeFactors -- (primeroYlongitud xs) es el par formado por el primer elemento de xs -- y la longitud de xs. Por ejemplo, -- primeroYlongitud [3,2,5,7] == (3,4) primeroYlongitud :: [a] -> (a,Integer) primeroYlongitud (x:xs) = (x, 1 + genericLength xs) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sumasDeDosAbundantes :: Positive Int -> Bool prop_sumasDeDosAbundantes (Positive n) = sumasDeDosAbundantes1 !! n == sumasDeDosAbundantes2 !! n -- La comprobación es -- λ> quickCheck prop_sumasDeDosAbundantes -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> sumasDeDosAbundantes1 !! (2*10^3) -- 2887 -- (2.54 secs, 516,685,168 bytes) -- λ> sumasDeDosAbundantes2 !! (2*10^3) -- 2887 -- (1.43 secs, 141,606,136 bytes) |
El código se encuentra en GitHub.



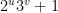 , para u y v enteros no negativos.
, para u y v enteros no negativos.