Continuación de Exercitium en GitHub
A partir del 29 de mayo de 2024, los nuevos problemas se publicarán en Exercitium en GitHub.
A partir del 29 de mayo de 2024, los nuevos problemas se publicarán en Exercitium en GitHub.
Dos números amigos son dos números positivos distintos tales que la suma de los divisores propios de cada uno es igual al otro. Los divisores propios de un número incluyen la unidad pero no al propio número. Por ejemplo, divisores propios de 220 son 1, 2, 4, 5, 10, 11, 20, 22, 44, 55 y 110. La suma de estos números equivale a 284. A su vez, los divisores propios de 284 son 1, 2, 4, 71 y 142. Su suma equivale a 220. Por tanto, 220 y 284 son amigos.
Definir la función
|
1 |
amigos :: Integer -> Integer -> Bool |
tal que amigos x y se verifica si los números x e y son amigos. Por ejemplo,
|
1 2 3 |
amigos 220 284 == True amigos 220 23 == False amigos 42262694537514864075544955198125 42405817271188606697466971841875 == True |
El hueco de un número primo p es la distancia entre p y primo siguiente de p. Por ejemplo, el hueco de 7 es 4 porque el primo siguiente de 7 es 11 y 4 = 11-7. Los huecos de los primeros números son
|
1 2 3 4 5 |
Primo Hueco 2 1 3 2 7 4 11 2 |
El hueco de un número primo p es maximal si es mayor que los huecos de todos los números menores que p. Por ejemplo, 4 es un hueco maximal de 7 ya que los huecos de los primos menores que 7 son 1 y 2 y ambos son menores que 4. La tabla de los primeros huecos maximales es
|
1 2 3 4 5 6 7 8 9 |
Primo Hueco 2 1 3 2 7 4 23 6 89 8 113 14 523 18 887 20 |
Definir la sucesión
|
1 |
primosYhuecosMaximales :: [(Integer,Integer)] |
cuyos elementos son los números primos con huecos maximales junto son sus huecos. Por ejemplo,
|
1 2 3 4 |
λ> take 8 primosYhuecosMaximales [(2,1),(3,2),(7,4),(23,6),(89,8),(113,14),(523,18),(887,20)] λ> primosYhuecosMaximales !! 20 (2010733,148) |
Un número de Hilbert es un entero positivo de la forma 4n+1. Los primeros números de Hilbert son 1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49, 53, 57, 61, 65, 69, 73, 77, 81, 85, 89, 93, 97, …
Un primo de Hilbert es un número de Hilbert n que no es divisible por ningún número de Hilbert menor que n (salvo el 1). Los primeros primos de Hilbert son 5, 9, 13, 17, 21, 29, 33, 37, 41, 49, 53, 57, 61, 69, 73, 77, 89, 93, 97, 101, 109, 113, 121, 129, 133, 137, 141, 149, 157, 161, 173, 177, 181, 193, 197, …
Definir la sucesión
|
1 |
primosH :: [Integer] |
tal que sus elementos son los primos de Hilbert. Por ejemplo,
|
1 2 |
take 15 primosH == [5,9,13,17,21,29,33,37,41,49,53,57,61,69,73] primosH !! (3*10^4) == 313661 |
Definir la función
|
1 |
sumaDeCuadrados :: Integer -> Integer |
tal que sumaDeCuadrados n es la suma de los cuadrados de los primeros n números; es decir, 1² + 2² + … + n². Por ejemplo,
|
1 2 3 |
sumaDeCuadrados 3 == 14 sumaDeCuadrados 100 == 338350 length (show (sumaDeCuadrados (10^100))) == 300 |
Soluciones
A continuación se muestran las soluciones en Haskell y las soluciones en Python.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
import Data.List (foldl') import Test.QuickCheck -- 1ª solución -- =========== sumaDeCuadrados1 :: Integer -> Integer sumaDeCuadrados1 n = sum [x^2 | x <- [1..n]] -- 2ª solución -- =========== sumaDeCuadrados2 :: Integer -> Integer sumaDeCuadrados2 n = n*(n+1)*(2*n+1) `div` 6 -- 3ª solución -- =========== sumaDeCuadrados3 :: Integer -> Integer sumaDeCuadrados3 1 = 1 sumaDeCuadrados3 n = n^2 + sumaDeCuadrados3 (n-1) -- 4ª solución -- =========== sumaDeCuadrados4 :: Integer -> Integer sumaDeCuadrados4 n = foldl (+) 0 (map (^2) [0..n]) -- 5ª solución -- =========== sumaDeCuadrados5 :: Integer -> Integer sumaDeCuadrados5 n = foldl' (+) 0 (map (^2) [0..n]) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sumaDeCuadrados :: Positive Integer -> Bool prop_sumaDeCuadrados (Positive n) = all (== sumaDeCuadrados1 n) [sumaDeCuadrados2 n, sumaDeCuadrados3 n, sumaDeCuadrados4 n, sumaDeCuadrados5 n] -- La comprobación es -- λ> quickCheck prop_sumaDeCuadrados -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> sumaDeCuadrados1 (2*10^6) -- 2666668666667000000 -- (1.90 secs, 1,395,835,576 bytes) -- λ> sumaDeCuadrados2 (2*10^6) -- 2666668666667000000 -- (0.01 secs, 563,168 bytes) -- λ> sumaDeCuadrados3 (2*10^6) -- 2666668666667000000 -- (2.37 secs, 1,414,199,400 bytes) -- λ> sumaDeCuadrados4 (2*10^6) -- 2666668666667000000 -- (1.33 secs, 1,315,836,128 bytes) -- λ> sumaDeCuadrados5 (2*10^6) -- 2666668666667000000 -- (0.71 secs, 1,168,563,384 bytes) |
El código se encuentra en GitHub.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
from operator import add from functools import reduce from sys import setrecursionlimit from timeit import Timer, default_timer from hypothesis import given, strategies as st setrecursionlimit(10**6) # 1ª solución # =========== def sumaDeCuadrados1(n: int) -> int: return sum(x**2 for x in range(1, n + 1)) # 2ª solución # =========== def sumaDeCuadrados2(n: int) -> int: return n * (n + 1) * (2 * n + 1) // 6 # 3ª solución # =========== def sumaDeCuadrados3(n: int) -> int: if n == 1: return 1 return n**2 + sumaDeCuadrados3(n - 1) # 4ª solución # =========== def sumaDeCuadrados4(n: int) -> int: return reduce(add, (x**2 for x in range(1, n + 1))) # 5ª solución # =========== def sumaDeCuadrados5(n: int) -> int: x, r = 1, 0 while x <= n: r = r + x**2 x = x + 1 return r # 6ª solución # =========== def sumaDeCuadrados6(n: int) -> int: r = 0 for x in range(1, n + 1): r = r + x**2 return r # Comprobación de equivalencia # ============================ # La propiedad es @given(st.integers(min_value=1, max_value=1000)) def test_sumaDeCuadrados(n): r = sumaDeCuadrados1(n) assert sumaDeCuadrados2(n) == r assert sumaDeCuadrados3(n) == r assert sumaDeCuadrados4(n) == r assert sumaDeCuadrados5(n) == r assert sumaDeCuadrados6(n) == r # La comprobación es # src> poetry run pytest -q suma_de_los_cuadrados_de_los_primeros_numeros_naturales.py # 1 passed in 0.19s # Comparación de eficiencia # ========================= def tiempo(e): """Tiempo (en segundos) de evaluar la expresión e.""" t = Timer(e, "", default_timer, globals()).timeit(1) print(f"{t:0.2f} segundos") # La comparación es # >>> tiempo('sumaDeCuadrados1(20000)') # 0.01 segundos # >>> tiempo('sumaDeCuadrados2(20000)') # 0.00 segundos # >>> tiempo('sumaDeCuadrados3(20000)') # 0.02 segundos # >>> tiempo('sumaDeCuadrados4(20000)') # 0.02 segundos # >>> tiempo('sumaDeCuadrados5(20000)') # 0.02 segundos # >>> tiempo('sumaDeCuadrados6(20000)') # 0.02 segundos # # >>> tiempo('sumaDeCuadrados1(10**7)') # 2.19 segundos # >>> tiempo('sumaDeCuadrados2(10**7)') # 0.00 segundos # >>> tiempo('sumaDeCuadrados4(10**7)') # 2.48 segundos # >>> tiempo('sumaDeCuadrados5(10**7)') # 2.53 segundos # >>> tiempo('sumaDeCuadrados6(10**7)') # 2.22 segundos |
El código se encuentra en GitHub.
Los números de Fibonacci se definen mediante las ecuaciones
|
1 2 3 |
F(0) = 0 F(1) = 1 F(n) = F(n-1) + F(n-2), si n > 1 |
Los primeros números de Fibonacci son
|
1 |
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, ... |
Una generalización de los anteriores son los números de Pentanacci definidos por las siguientes ecuaciones
|
1 2 3 4 5 6 |
P(0) = 0 P(1) = 1 P(2) = 1 P(3) = 2 P(4) = 4 P(n) = P(n-1) + P(n-2) + P(n-3) + P(n-4) + P(n-5), si n > 4 |
Los primeros números de Pentanacci son
|
1 |
0, 1, 1, 2, 4, 8, 16, 31, 61, 120, 236, 464, 912, 1793, 3525, ... |
Definir la sucesión
|
1 |
pentanacci :: [Integer] |
cuyos elementos son los números de Pentanacci. Por ejemplo,
|
1 2 3 4 5 6 7 |
λ> take 15 pentanacci [0,1,1,2,4,8,16,31,61,120,236,464,912,1793,3525] λ> (pentanacci !! (10^5)) `mod` (10^30) 482929150584077921552549215816 231437922897686901289110700696 λ> length (show (pentanacci !! (10^5))) 29357 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
import Data.List (zipWith5) import Test.QuickCheck (NonNegative (NonNegative), quickCheckWith, maxSize, stdArgs) -- 1ª solución -- =========== pentanacci1 :: [Integer] pentanacci1 = [pent n | n <- [0..]] pent :: Integer -> Integer pent 0 = 0 pent 1 = 1 pent 2 = 1 pent 3 = 2 pent 4 = 4 pent n = pent (n-1) + pent (n-2) + pent (n-3) + pent (n-4) + pent (n-5) -- 2ª solución -- =========== pentanacci2 :: [Integer] pentanacci2 = 0 : 1 : 1 : 2 : 4 : zipWith5 f (r 0) (r 1) (r 2) (r 3) (r 4) where f a b c d e = a+b+c+d+e r n = drop n pentanacci2 -- 3ª solución -- =========== pentanacci3 :: [Integer] pentanacci3 = p (0, 1, 1, 2, 4) where p (a, b, c, d, e) = a : p (b, c, d, e, a + b + c + d + e) -- 4ª solución -- =========== pentanacci4 :: [Integer] pentanacci4 = 0: 1: 1: 2: 4: p pentanacci4 where p (a:b:c:d:e:xs) = (a+b+c+d+e): p (b:c:d:e:xs) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_pentanacci :: NonNegative Int -> Bool prop_pentanacci (NonNegative n) = all (== pentanacci1 !! n) [pentanacci1 !! n, pentanacci2 !! n, pentanacci3 !! n] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=25}) prop_pentanacci -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> pentanacci1 !! 25 -- 5976577 -- (3.18 secs, 1,025,263,896 bytes) -- λ> pentanacci2 !! 25 -- 5976577 -- (0.00 secs, 562,360 bytes) -- -- λ> length (show (pentanacci2 !! (10^5))) -- 29357 -- (1.04 secs, 2,531,259,408 bytes) -- λ> length (show (pentanacci3 !! (10^5))) -- 29357 -- (1.00 secs, 2,548,868,384 bytes) -- λ> length (show (pentanacci4 !! (10^5))) -- 29357 -- (0.96 secs, 2,580,065,520 bytes) |
El código se encuentra en GitHub.
Sea 
$$n = 2^{a} \times p(1)^{b(1)} \times \dots \times p(n)^{b(n)} \times q(1)^{c(1)} \times \dots \times q(m)^{c(m)}$$
donde los 
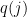
cuadrados es 0, si algún 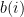
$$\frac{(1+c(1)) \times \dots \times (1+c(m))}{2}$$
en caso contrario. Por ejemplo, el número
$$2^{3} \times (3^{9} \times 7^{8}) \times (5^{3} \times 13^{6})$$
no se puede descomponer como sumas de dos cuadrados (porque el exponente de 3 es impar) y el número
$$2^{3} \times (3^{2} \times 7^{8}) \times (5^{3} \times 13^{6})$$
tiene 14 descomposiciones como suma de dos cuadrados (porque los exponentes de 3 y 7 son pares y el techo de
$$\frac{(1+3) \times (1+6)}{2}$$
es 14).
Definir la función
|
1 |
nRepresentaciones :: Integer -> Integer |
tal que (nRepresentaciones n) es el número de formas de representar n como suma de dos cuadrados. Por ejemplo,
|
1 2 3 |
nRepresentaciones (2^3*3^9*5^3*7^8*13^6) == 0 nRepresentaciones (2^3*3^2*5^3*7^8*13^6) == 14 head [n | n <- [1..], nRepresentaciones n > 8] == 71825 |
Usando la función representaciones del ejercicio anterior, comprobar con QuickCheck la siguiente propiedad
|
1 2 3 |
prop_representacion :: Positive Integer -> Bool prop_representacion (Positive n) = nRepresentaciones2 n == genericLength (representaciones n) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
import Data.List (genericLength, group) import Data.Numbers.Primes (primeFactors) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== nRepresentaciones1 :: Integer -> Integer nRepresentaciones1 n = ceiling (fromIntegral (product (map aux (factorizacion n))) / 2) where aux (p,e) | p == 2 = 1 | p `mod` 4 == 3 = if even e then 1 else 0 | otherwise = e+1 -- (factorizacion n) es la factorización prima de n. Por ejemplo, -- factorizacion 600 == [(2,3),(3,1),(5,2)] factorizacion :: Integer -> [(Integer,Integer)] factorizacion n = map (\xs -> (head xs, genericLength xs)) (group (primeFactors n)) -- 2ª solución -- =========== nRepresentaciones2 :: Integer -> Integer nRepresentaciones2 n = (1 + product (map aux (factorizacion n))) `div` 2 where aux (p,e) | p == 2 = 1 | p `mod` 4 == 3 = if even e then 1 else 0 | otherwise = e+1 -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_nRepresentaciones :: Positive Integer -> Bool prop_nRepresentaciones (Positive n) = nRepresentaciones1 n == nRepresentaciones2 n -- La comprobación es -- λ> quickCheck prop_nRepresentaciones -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> head [n | n <- [1..], nRepresentaciones1 n > 8] -- 71825 -- (1.39 secs, 2,970,063,760 bytes) -- λ> head [n | n <- [1..], nRepresentaciones2 n > 8] -- 71825 -- (1.71 secs, 2,943,788,424 bytes) -- Comprobación de la propiedad -- ============================ -- La propiedad es prop_representacion :: Positive Integer -> Bool prop_representacion (Positive n) = nRepresentaciones2 n == genericLength (representaciones n) representaciones :: Integer -> [(Integer,Integer)] representaciones n = [(x,raiz z) | x <- [0..raiz (n `div` 2)], let z = n - x*x, esCuadrado z] esCuadrado :: Integer -> Bool esCuadrado x = x == y * y where y = raiz x raiz :: Integer -> Integer raiz x = floor (sqrt (fromIntegral x)) -- La comprobación es -- λ> quickCheck prop_representacion -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Definir la función
|
1 |
representaciones :: Integer -> [(Integer,Integer)] |
tal que (representaciones n) es la lista de pares de números naturales (x,y) tales que n = x^2 + y^2. Por ejemplo.
|
1 2 3 4 |
representaciones 20 == [(2,4)] representaciones 25 == [(0,5),(3,4)] representaciones 325 == [(1,18),(6,17),(10,15)] length (representaciones (10^14)) == 8 |
Comprobar con QuickCheck que un número natural n se puede como suma de dos cuadrados si, y sólo si, en la factorización prima de n todos los exponentes de sus factores primos congruentes con 3 módulo 4 son pares.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
import Data.List (genericLength, group) import Data.Numbers.Primes (primeFactors) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== representaciones1 :: Integer -> [(Integer,Integer)] representaciones1 n = [(x,y) | x <- [0..n], y <- [x..n], n == x*x + y*y] -- 2ª solución -- =========== representaciones2 :: Integer -> [(Integer,Integer)] representaciones2 n = [(x,raiz z) | x <- [0..raiz (n `div` 2)], let z = n - x*x, esCuadrado z] -- (raiz x) es la raíz cuadrada entera de x. Por ejemplo, -- raiz 25 == 5 -- raiz 24 == 4 -- raiz 26 == 5 raiz :: Integer -> Integer raiz = floor . sqrt . fromIntegral -- (esCuadrado x) se verifica si x es un número al cuadrado. Por -- ejemplo, -- esCuadrado 25 == True -- esCuadrado 26 == False esCuadrado :: Integer -> Bool esCuadrado x = x == y * y where y = raiz x -- 3ª solución -- =========== representaciones3 :: Integer -> [(Integer, Integer)] representaciones3 n = aux 0 (raiz n) where aux x y | x > y = [] | otherwise = case compare (x*x + y*y) n of LT -> aux (x + 1) y EQ -> (x, y) : aux (x + 1) (y - 1) GT -> aux x (y - 1) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_representaciones :: Positive Integer -> Bool prop_representaciones (Positive n) = all (== representaciones1 n) [representaciones2 n, representaciones3 n] -- La comprobación es -- λ> quickCheck prop_representaciones -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> representaciones1 4000 -- [(20,60),(36,52)] -- (4.95 secs, 2,434,929,624 bytes) -- λ> representaciones2 4000 -- [(20,60),(36,52)] -- (0.00 secs, 599,800 bytes) -- λ> representaciones3 4000 -- [(20,60),(36,52)] -- (0.01 secs, 591,184 bytes) -- -- λ> length (representaciones2 (10^14)) -- 8 -- (6.64 secs, 5,600,837,088 bytes) -- λ> length (representaciones3 (10^14)) -- 8 -- (9.37 secs, 4,720,548,264 bytes) -- Comprobación de la propiedad -- ============================ -- La propiedad es prop_representacion :: Positive Integer -> Bool prop_representacion (Positive n) = not (null (representaciones2 n)) == all (\(p,e) -> p `mod` 4 /= 3 || even e) (factorizacion n) -- (factorizacion n) es la factorización prima de n. Por ejemplo, -- factorizacion 600 == [(2,3),(3,1),(5,2)] factorizacion :: Integer -> [(Integer,Integer)] factorizacion n = map (\xs -> (head xs, genericLength xs)) (group (primeFactors n)) -- La comprobación es -- λ> quickCheck prop_representacion -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Un número de Hilbert es un entero positivo de la forma 4n+1. Los primeros números de Hilbert son 1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49, 53, 57, 61, 65, 69, …
Un primo de Hilbert es un número de Hilbert n que no es por ningún número de Hilbert menor que n (salvo el 1). Los primeros primos de Hilbert son 5, 9, 13, 17, 21, 29, 33, 37, 41, 49, 53, 57, 61, 69, 73, 77, 89, 93, 97, 101, 109, 113, 121, 129, 133, 137, …
Definir la función
|
1 |
factorizacionesH :: Integer -> [[Integer]] |
tal que (factorizacionesH n) es la listas de primos de Hilbert cuyo producto es el número de Hilbert n. Por ejemplo,
|
1 2 3 4 |
factorizacionesH 25 == [[5,5]] factorizacionesH 45 == [[5,9]] factorizacionesH 441 == [[9,49],[21,21]] factorizacionesH 80109 == [[9,9,989],[9,69,129]] |
Comprobar con QuickCheck que todos los números de Hilbert son factorizables como producto de primos de Hilbert (aunque la factorización, como para el 441, puede no ser única).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
import Data.Numbers.Primes (isPrime, primeFactors) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== factorizacionesH1 :: Integer -> [[Integer]] factorizacionesH1 = aux primosH1 where aux (x:xs) n | x == n = [[n]] | x > n = [] | n `mod` x == 0 = map (x:) (aux (x:xs) (n `div` x) ) ++ aux xs n | otherwise = aux xs n primosH1 :: [Integer] primosH1 = [n | n <- tail numerosH, divisoresH n == [1,n]] -- numerosH es la sucesión de los números de Hilbert. Por ejemplo, -- take 15 numerosH == [1,5,9,13,17,21,25,29,33,37,41,45,49,53,57] numerosH :: [Integer] numerosH = [1,5..] -- (divisoresH n) es la lista de los números de Hilbert que dividen a -- n. Por ejemplo, -- divisoresH 117 == [1,9,13,117] -- divisoresH 21 == [1,21] divisoresH :: Integer -> [Integer] divisoresH n = [x | x <- takeWhile (<=n) numerosH, n `mod` x == 0] -- 2ª solución -- =========== factorizacionesH2 :: Integer -> [[Integer]] factorizacionesH2 = aux primosH2 where aux (x:xs) n | x == n = [[n]] | x > n = [] | n `mod` x == 0 = map (x:) (aux (x:xs) (n `div` x) ) ++ aux xs n | otherwise = aux xs n primosH2 :: [Integer] primosH2 = filter esPrimoH (tail numerosH) where esPrimoH n = all noDivideAn [5,9..m] where noDivideAn x = n `mod` x /= 0 m = ceiling (sqrt (fromIntegral n)) -- 3ª solución -- =========== -- Basada en la siguiente propiedad: Un primo de Hilbert es un primo -- de la forma 4n + 1 o un semiprimo de la forma (4a + 3) × (4b + 3) -- (ver en https://bit.ly/3zq7h4e ). factorizacionesH3 :: Integer -> [[Integer]] factorizacionesH3 = aux primosH3 where aux (x:xs) n | x == n = [[n]] | x > n = [] | n `mod` x == 0 = map (x:) (aux (x:xs) (n `div` x) ) ++ aux xs n | otherwise = aux xs n primosH3 :: [Integer] primosH3 = [ n | n <- numerosH, isPrime n || semiPrimoH n ] where semiPrimoH n = length xs == 2 && all (\x -> (x-3) `mod` 4 == 0) xs where xs = primeFactors n -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_factorizacionesH :: Positive Integer -> Bool prop_factorizacionesH (Positive n) = all (== factorizacionesH1 m) [factorizacionesH2 m, factorizacionesH3 m] where m = 1 + 4 * n -- La comprobación es -- λ> quickCheck prop_factorizacionesH -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> factorizacionesH1 80109 -- [[9,9,989],[9,69,129]] -- (42.77 secs, 14,899,787,640 bytes) -- λ> factorizacionesH2 80109 -- [[9,9,989],[9,69,129]] -- (0.26 secs, 156,051,104 bytes) -- λ> factorizacionesH3 80109 -- [[9,9,989],[9,69,129]] -- (0.35 secs, 1,118,236,536 bytes) -- Propiedad de factorización -- ========================== -- La propiedad es prop_factorizable :: Positive Integer -> Bool prop_factorizable (Positive n) = not (null (factorizacionesH1 (1 + 4 * n))) -- La comprobación es -- λ> quickCheck prop_factorizable -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Basado en el artículo Failure of unique factorization (A example of the failure of the fundamental theorem of arithmetic) de R.J. Lipton en el blog Gödel’s Lost Letter and P=NP.
Otras referencias
Un número de Hilbert es un positivo de la forma 4n+1. Los primeros números de Hilbert son 1, 5, 9, 13, 17, 21, 25, 29, 33, 37, 41, 45, 49, 53, 57, 61, 65, 69, 73, 77, 81, 85, 89, 93, 97, …
Un primo de Hilbert es un número de Hilbert n que no es por ningún número de Hilbert menor que n (salvo el 1). Los primeros primos de Hilbert son 5, 9, 13, 17, 21, 29, 33, 37, 41, 49, 53, 57, 61, 69, 73, 77, 89, 93, 97, 101, 109, 113, 121, 129, 133, 137, 141, 149, 157, 161, 173, 177, 181, 193, 197, …
Definir la sucesión
|
1 |
primosH :: [Integer] |
tal que sus elementos son los primos de Hilbert. Por ejemplo,
|
1 2 |
take 15 primosH == [5,9,13,17,21,29,33,37,41,49,53,57,61,69,73] primosH !! (3*10^4) == 313661 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
import Data.Numbers.Primes (isPrime, primeFactors) import Test.QuickCheck (NonNegative (NonNegative), quickCheck) -- 1ª solución -- =========== primosH1 :: [Integer] primosH1 = [n | n <- tail numerosH, divisoresH n == [1,n]] -- numerosH es la sucesión de los números de Hilbert. Por ejemplo, -- take 15 numerosH == [1,5,9,13,17,21,25,29,33,37,41,45,49,53,57] numerosH :: [Integer] numerosH = [1,5..] -- (divisoresH n) es la lista de los números de Hilbert que dividen a -- n. Por ejemplo, -- divisoresH 117 == [1,9,13,117] -- divisoresH 21 == [1,21] divisoresH :: Integer -> [Integer] divisoresH n = [x | x <- takeWhile (<=n) numerosH, n `mod` x == 0] -- 2ª solución -- =========== primosH2 :: [Integer] primosH2 = filter esPrimoH (tail numerosH) where esPrimoH n = all noDivideAn [5,9..m] where noDivideAn x = n `mod` x /= 0 m = ceiling (sqrt (fromIntegral n)) -- 3ª solución -- =========== -- Basada en la siguiente propiedad: Un primo de Hilbert es un primo -- de la forma 4n + 1 o un semiprimo de la forma (4a + 3) × (4b + 3) -- (ver en https://bit.ly/3zq7h4e ). primosH3 :: [Integer] primosH3 = [ n | n <- numerosH, isPrime n || semiPrimoH n ] where semiPrimoH n = length xs == 2 && all (\x -> (x-3) `mod` 4 == 0) xs where xs = primeFactors n -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_primosH :: NonNegative Int -> Bool prop_primosH (NonNegative n) = all (== primosH1 !! n) [primosH2 !! n, primosH3 !! n] -- La comprobación es -- λ> quickCheck prop_primosH -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> primosH1 !! 2000 -- 16957 -- (2.16 secs, 752,085,752 bytes) -- λ> primosH2 !! 2000 -- 16957 -- (0.03 secs, 19,771,008 bytes) -- λ> primosH3 !! 2000 -- 16957 -- (0.07 secs, 152,029,168 bytes) -- -- λ> primosH2 !! (3*10^4) -- 313661 -- (1.44 secs, 989,761,888 bytes) -- λ> primosH3 !! (3*10^4) -- 313661 -- (2.06 secs, 6,554,068,992 bytes) |
El código se encuentra en GitHub.
Definir la sucesión
|
1 |
sumasDeDosPrimos :: [Integer] |
cuyos elementos son los números que se pueden escribir como suma de dos números primos. Por ejemplo,
|
1 2 3 4 |
λ> take 23 sumasDeDosPrimos [4,5,6,7,8,9,10,12,13,14,15,16,18,19,20,21,22,24,25,26,28,30,31] λ> sumasDeDosPrimos !! (5*10^5) 862878 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
import Data.Numbers.Primes (isPrime, primes) import Test.QuickCheck -- 1ª solución -- =========== sumasDeDosPrimos1 :: [Integer] sumasDeDosPrimos1 = [n | n <- [1..], not (null (sumaDeDosPrimos1 n))] -- (sumaDeDosPrimos1 n) es la lista de pares de primos cuya suma es -- n. Por ejemplo, -- sumaDeDosPrimos 9 == [(2,7),(7,2)] -- sumaDeDosPrimos 16 == [(3,13),(5,11),(11,5),(13,3)] -- sumaDeDosPrimos 17 == [] sumaDeDosPrimos1 :: Integer -> [(Integer,Integer)] sumaDeDosPrimos1 n = [(x,n-x) | x <- primosN, isPrime (n-x)] where primosN = takeWhile (< n) primes -- 2ª solución -- =========== sumasDeDosPrimos2 :: [Integer] sumasDeDosPrimos2 = [n | n <- [1..], not (null (sumaDeDosPrimos2 n))] -- (sumasDeDosPrimos2 n) es la lista de pares (x,y) de primos cuya suma -- es n y tales que x <= y. Por ejemplo, -- sumaDeDosPrimos2 9 == [(2,7)] -- sumaDeDosPrimos2 16 == [(3,13),(5,11)] -- sumaDeDosPrimos2 17 == [] sumaDeDosPrimos2 :: Integer -> [(Integer,Integer)] sumaDeDosPrimos2 n = [(x,n-x) | x <- primosN, isPrime (n-x)] where primosN = takeWhile (<= (n `div` 2)) primes -- 3ª solución -- =========== sumasDeDosPrimos3 :: [Integer] sumasDeDosPrimos3 = filter esSumaDeDosPrimos3 [4..] -- (esSumaDeDosPrimos3 n) se verifica si n es suma de dos primos. Por -- ejemplo, -- esSumaDeDosPrimos3 9 == True -- esSumaDeDosPrimos3 16 == True -- esSumaDeDosPrimos3 17 == False esSumaDeDosPrimos3 :: Integer -> Bool esSumaDeDosPrimos3 n | odd n = isPrime (n-2) | otherwise = any isPrime [n-x | x <- takeWhile (<= (n `div` 2)) primes] -- 4ª solución -- =========== -- Usando la conjetura de Goldbach que dice que "Todo número par mayor -- que 2 puede escribirse como suma de dos números primos" . sumasDeDosPrimos4 :: [Integer] sumasDeDosPrimos4 = filter esSumaDeDosPrimos4 [4..] -- (esSumaDeDosPrimos4 n) se verifica si n es suma de dos primos. Por -- ejemplo, -- esSumaDeDosPrimos4 9 == True -- esSumaDeDosPrimos4 16 == True -- esSumaDeDosPrimos4 17 == False esSumaDeDosPrimos4 :: Integer -> Bool esSumaDeDosPrimos4 n = even n || isPrime (n-2) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sumasDeDosPrimos :: NonNegative Int -> Bool prop_sumasDeDosPrimos (NonNegative n) = all (== sumasDeDosPrimos1 !! n) [sumasDeDosPrimos2 !! n, sumasDeDosPrimos3 !! n, sumasDeDosPrimos4 !! n] -- La comprobación es -- λ> quickCheck prop_sumasDeDosPrimos -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> sumasDeDosPrimos1 !! 5000 -- 7994 -- (2.61 secs, 9,299,106,792 bytes) -- λ> sumasDeDosPrimos2 !! 5000 -- 7994 -- (1.48 secs, 5,190,651,760 bytes) -- λ> sumasDeDosPrimos3 !! 5000 -- 7994 -- (0.12 secs, 351,667,104 bytes) -- λ> sumasDeDosPrimos4 !! 5000 -- 7994 -- (0.04 secs, 63,464,320 bytes) -- -- λ> sumasDeDosPrimos3 !! (5*10^4) -- 83674 -- (2.23 secs, 7,776,049,264 bytes) -- λ> sumasDeDosPrimos4 !! (5*10^4) -- 83674 -- (0.34 secs, 1,183,604,984 bytes) |
El código se encuentra en GitHub.
La serie de Thue-Morse comienza con el término [0] y sus siguientes términos se construyen añadiéndole al anterior su complementario. Los primeros términos de la serie son
|
1 2 3 4 5 |
[0] [0,1] [0,1,1,0] [0,1,1,0,1,0,0,1] [0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0] |
De esta forma se va formando una sucesión
|
1 |
0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0,... |
que se conoce como la sucesión de Thue-Morse.
Definir la sucesión
|
1 |
sucThueMorse :: [Int] |
cuyos elementos son los de la sucesión de Thue-Morse. Por ejemplo,
|
1 2 3 4 5 6 |
λ> take 30 sucThueMorse [0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0,1,0,0,1,0,1,1,0,0,1,1,0,1,0] λ> map (sucThueMorse4 !!) [1234567..1234596] [1,1,0,0,1,0,1,1,0,1,0,0,1,0,1,1,0,0,1,1,0,1,0,0,1,1,0,0,1,0] λ> map (sucThueMorse4 !!) [4000000..4000030] [1,0,0,1,0,1,1,0,0,1,1,0,1,0,0,1,0,1,1,0,1,0,0,1,1,0,0,1,0,1,1] |
Comprobar con QuickCheck que si s(n) representa el término n-ésimo de la sucesión de Thue-Morse, entonces
|
1 2 |
s(2n) = s(n) s(2n+1) = 1 - s(n) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
import Test.QuickCheck -- 1ª solución -- =========== sucThueMorse1 :: [Int] sucThueMorse1 = map termSucThueMorse1 [0..] -- (termSucThueMorse1 n) es el n-ésimo término de la sucesión de -- Thue-Morse. Por ejemplo, -- termSucThueMorse1 0 == 0 -- termSucThueMorse1 1 == 1 -- termSucThueMorse1 2 == 1 -- termSucThueMorse1 3 == 0 -- termSucThueMorse1 4 == 1 termSucThueMorse1 :: Int -> Int termSucThueMorse1 0 = 0 termSucThueMorse1 n = (serieThueMorse !! k) !! n where k = 1 + floor (logBase 2 (fromIntegral n)) -- serieThueMorse es la lista cuyos elementos son los términos de la -- serie de Thue-Morse. Por ejemplo, -- λ> take 4 serieThueMorse3 -- [[0],[0,1],[0,1,1,0],[0,1,1,0,1,0,0,1]] serieThueMorse :: [[Int]] serieThueMorse = iterate paso [0] where paso xs = xs ++ map (1-) xs -- 2ª solución -- =========== sucThueMorse2 :: [Int] sucThueMorse2 = 0 : intercala (map (1-) sucThueMorse2) (tail sucThueMorse2) -- (intercala xs ys) es la lista obtenida intercalando los elementos de -- las listas infinitas xs e ys. Por ejemplo, -- take 10 (intercala [1,5..] [2,4..]) == [1,2,5,4,9,6,13,8,17,10] intercala :: [a] -> [a] -> [a] intercala (x:xs) ys = x : intercala ys xs -- 3ª solución -- =========== sucThueMorse3 :: [Int] sucThueMorse3 = 0 : 1 : aux (tail sucThueMorse3) where aux (x : xs) = x : (1 - x) : aux xs -- 4ª solución -- =========== sucThueMorse4 :: [Int] sucThueMorse4 = 0 : aux [1] where aux xs = xs ++ aux (xs ++ map (1-) xs) -- Comprobación de la propiedad -- ============================ -- La propiedad es prop_termSucThueMorse :: NonNegative Int -> Bool prop_termSucThueMorse (NonNegative n) = sucThueMorse1 !! (2*n) == sn && sucThueMorse1 !! (2*n+1) == 1 - sn where sn = sucThueMorse1 !! n -- La comprobación es -- λ> quickCheck prop_termSucThueMorse -- +++ OK, passed 100 tests. -- 5ª solución -- =========== sucThueMorse5 :: [Int] sucThueMorse5 = map termSucThueMorse5 [0..] -- (termSucThueMorse5 n) es el n-ésimo término de la sucesión de -- Thue-Morse. Por ejemplo, -- termSucThueMorse5 0 == 0 -- termSucThueMorse5 1 == 1 -- termSucThueMorse5 2 == 1 -- termSucThueMorse5 3 == 0 -- termSucThueMorse5 4 == 1 termSucThueMorse5 :: Int -> Int termSucThueMorse5 0 = 0 termSucThueMorse5 n | even n = termSucThueMorse5 (n `div` 2) | otherwise = 1 - termSucThueMorse5 (n `div` 2) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sucThueMorse :: NonNegative Int -> Bool prop_sucThueMorse (NonNegative n) = all (== sucThueMorse1 !! n) [sucThueMorse2 !! n, sucThueMorse3 !! n, sucThueMorse4 !! n, sucThueMorse5 !! n] -- La comprobación es -- λ> quickCheck prop_sucThueMorse -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> sucThueMorse1 !! (10^7) -- 0 -- (3.28 secs, 3,420,080,168 bytes) -- λ> sucThueMorse2 !! (10^7) -- 0 -- (3.01 secs, 1,720,549,640 bytes) -- λ> sucThueMorse3 !! (10^7) -- 0 -- (1.80 secs, 1,360,550,040 bytes) -- λ> sucThueMorse4 !! (10^7) -- 0 -- (0.88 secs, 1,254,772,768 bytes) -- λ> sucThueMorse5 !! (10^7) -- 0 -- (0.62 secs, 1,600,557,072 bytes) |
El código se encuentra en GitHub.
La serie de Thue-Morse comienza con el término [0] y sus siguientes términos se construyen añadiéndole al anterior su complementario (es decir, la lista obtenida cambiando el 0 por 1 y el 1 por 0). Los primeros términos de la serie son
|
1 2 3 4 5 |
[0] [0,1] [0,1,1,0] [0,1,1,0,1,0,0,1] [0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0] |
Definir la lista
|
1 |
serieThueMorse :: [[Int]] |
tal que sus elementos son los términos de la serie de Thue-Morse. Por ejemplo,
|
1 2 |
λ> take 4 serieThueMorse [[0],[0,1],[0,1,1,0],[0,1,1,0,1,0,0,1]] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
import Test.QuickCheck (NonNegative (NonNegative), quickCheckWith, maxSize, stdArgs) -- 1ª solución -- =========== serieThueMorse1 :: [[Int]] serieThueMorse1 = map termSerieThueMorse [0..] -- (termSerieThueMorse n) es el término n-ésimo de la serie de -- Thue-Morse. Por ejemplo, -- termSerieThueMorse 1 == [0,1] -- termSerieThueMorse 2 == [0,1,1,0] -- termSerieThueMorse 3 == [0,1,1,0,1,0,0,1] -- termSerieThueMorse 4 == [0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0] termSerieThueMorse :: Int -> [Int] termSerieThueMorse 0 = [0] termSerieThueMorse n = xs ++ complementaria xs where xs = termSerieThueMorse (n-1) -- (complementaria xs) es la complementaria de la lista xs (formada por -- ceros y unos); es decir, la lista obtenida cambiando el 0 por 1 y el -- 1 por 0. Por ejemplo, -- complementaria [1,0,0,1,1,0,1] == [0,1,1,0,0,1,0] complementaria :: [Int] -> [Int] complementaria = map (1-) -- 2ª solución -- =========== serieThueMorse2 :: [[Int]] serieThueMorse2 = [0] : map paso serieThueMorse2 where paso xs = xs ++ complementaria xs -- 3ª solución -- =========== serieThueMorse3 :: [[Int]] serieThueMorse3 = iterate paso [0] where paso xs = xs ++ complementaria xs -- 4ª solución -- =========== -- Observando que cada término de la serie de Thue-Morse se obtiene del -- anterior sustituyendo los 1 por 1, 0 y los 0 por 0, 1. serieThueMorse4 :: [[Int]] serieThueMorse4 = [0] : map (concatMap paso4) serieThueMorse4 where paso4 x = [x,1-x] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_serieThueMorse :: NonNegative Int -> Bool prop_serieThueMorse (NonNegative n) = all (== serieThueMorse1 !! n) [serieThueMorse2 !! n, serieThueMorse3 !! n, serieThueMorse4 !! n] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=20}) prop_serieThueMorse -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> (serieThueMorse1 !! 23) !! (2^22) -- 1 -- (1.08 secs, 839,419,224 bytes) -- λ> (serieThueMorse2 !! 23) !! (2^22) -- 1 -- (0.61 secs, 839,413,592 bytes) -- λ> (serieThueMorse3 !! 23) !! (2^22) -- 1 -- (1.43 secs, 839,413,592 bytes) -- λ> (serieThueMorse4 !! 23) !! (2^22) -- 1 -- (1.57 secs, 1,007,190,024 bytes) |
El código se encuentra en [GitHub](https://github.com/jaalonso/Exercitium/blob/main/src/
Un número n es k-belga si la sucesión cuyo primer elemento es k y cuyos elementos se obtienen sumando reiteradamente las cifras de n contiene a n.
El 18 es 0-belga, porque a partir del 0 vamos a ir sumando sucesivamente 1, 8, 1, 8, … hasta llegar o sobrepasar el 18: 0, 1, 9, 10, 18, … Como se alcanza el 18, resulta que el 18 es 0-belga.
El 19 no es 1-belga, porque a partir del 1 vamos a ir sucesivamente 1, 9, 1, 9, … hasta llegar o sobrepasar el 18: 0, 1, 10, 11, 20, 21, … Como no se alcanza el 19, resulta que el 19 no es 1-belga.
Definir la función
|
1 |
esBelga :: Int -> Int -> Bool |
tal que (esBelga k n) se verifica si n es k-belga. Por ejemplo,
|
1 2 3 4 5 6 |
esBelga 0 18 == True esBelga 1 19 == False esBelga 0 2016 == True [x | x <- [0..30], esBelga 7 x] == [7,10,11,21,27,29] [x | x <- [0..30], esBelga 10 x] == [10,11,20,21,22,24,26] length [n | n <- [1..10^6], esBelga 0 n] == 272049 |
Comprobar con QuickCheck que para todo número entero positivo n, si k es el resto de n entre la suma de los dígitos de n, entonces n es k-belga.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import Data.Char (digitToInt) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== esBelga1 :: Int -> Int -> Bool esBelga1 k n = n == head (dropWhile (<n) (scanl (+) k (cycle (digitos n)))) digitos :: Int -> [Int] digitos n = map digitToInt (show n) -- 2ª solución -- =========== esBelga2 :: Int -> Int -> Bool esBelga2 k n = k <= n && n == head (dropWhile (<n) (scanl (+) (k + q * s) ds)) where ds = digitos n s = sum ds q = (n - k) `div` s -- Equivalencia -- ============ -- La propiedad es prop_esBelga :: Positive Int -> Positive Int -> Bool prop_esBelga (Positive k) (Positive n) = esBelga1 k n == esBelga2 k n -- La comprobación es -- λ> quickCheck prop_esBelga -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> length [n | n <- [1..2*10^4], esBelga1 0 n] -- 6521 -- (6.27 secs, 6,508,102,192 bytes) -- λ> length [n | n <- [1..2*10^4], esBelga2 0 n] -- 6521 -- (0.07 secs, 46,741,144 bytes) -- Verificación de la propiedad -- ============================ -- La propiedad es prop_Belga :: Positive Int -> Bool prop_Belga (Positive n) = esBelga2 k n where k = n `mod` sum (digitos n) -- La comprobación es -- λ> quickCheck prop_Belga -- +++ OK, passed 100 tests. |
Basado en el artículo Números belgas del blog Números y hoja de cálculo de Antonio Roldán Martínez.
El código se encuentra en GitHub.
El hueco de un número primo p es la distancia entre p y primo siguiente de p. Por ejemplo, el hueco de 7 es 4 porque el primo siguiente de 7 es 11 y 4 = 11-7. Los huecos de los primeros números son
|
1 2 3 4 5 |
Primo Hueco 2 1 3 2 7 4 11 2 |
El hueco de un número primo p es maximal si es mayor que huecos de todos los números menores que p. Por ejemplo, 4 es un hueco maximal de 7 ya que los huecos de los primos menores que 7 son 1 y 2 y ambos son menores que 4. La tabla de los primeros huecos maximales es
|
1 2 3 4 5 6 7 8 9 |
Primo Hueco 2 1 3 2 7 4 23 6 89 8 113 14 523 18 887 20 |
Definir la sucesión
|
1 |
primosYhuecosMaximales :: [(Integer,Integer)] |
cuyos elementos son los números primos con huecos maximales junto son sus huecos. Por ejemplo,
|
1 2 3 4 |
λ> take 8 primosYhuecosMaximales [(2,1),(3,2),(7,4),(23,6),(89,8),(113,14),(523,18),(887,20)] λ> primosYhuecosMaximales !! 20 (2010733,148) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import Data.Numbers.Primes (primes) import Test.QuickCheck (NonNegative (NonNegative), quickCheckWith, maxSize, stdArgs) -- 1ª solución -- =========== primosYhuecosMaximales1 :: [(Integer,Integer)] primosYhuecosMaximales1 = [(p,huecoPrimo p) | p <- primes, esMaximalHuecoPrimo p] -- (siguientePrimo x) es el menor primo mayor que x. Por ejemplo, -- siguientePrimo 7 == 11 -- siguientePrimo 8 == 11 siguientePrimo :: Integer -> Integer siguientePrimo p = head (dropWhile (<= p) primes) -- (huecoPrimo p) es la distancia del primo p hasta el siguiente -- primo. Por ejemplo, -- huecoPrimo 7 == 4 huecoPrimo :: Integer -> Integer huecoPrimo p = siguientePrimo p - p -- (esMaximalHuecoPrimo p) se verifica si el hueco primo de p es -- maximal. Por ejemplo, -- esMaximalHuecoPrimo 7 == True -- esMaximalHuecoPrimo 11 == False esMaximalHuecoPrimo :: Integer -> Bool esMaximalHuecoPrimo p = and [huecoPrimo n < h | n <- takeWhile (< p) primes] where h = huecoPrimo p -- 2ª solución -- =========== primosYhuecosMaximales2 :: [(Integer,Integer)] primosYhuecosMaximales2 = aux primosYhuecos where aux ((x,y):ps) = (x,y) : aux (dropWhile (\(_,b) -> b <= y) ps) -- primosYhuecos es la lista de los números primos junto son sus -- huecos. Por ejemplo, -- λ> take 10 primosYhuecos -- [(2,1),(3,2),(5,2),(7,4),(11,2),(13,4),(17,2),(19,4),(23,6),(29,2)] primosYhuecos :: [(Integer,Integer)] primosYhuecos = [(x,y-x) | (x,y) <- zip primes (tail primes)] -- 3ª solución -- =========== primosYhuecosMaximales3 :: [(Integer,Integer)] primosYhuecosMaximales3 = aux 0 primes where aux n (x:y:zs) | y-x > n = (x,y-x) : aux (y-x) (y:zs) | otherwise = aux n (y:zs) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_primosYhuecosMaximales :: NonNegative Int -> Bool prop_primosYhuecosMaximales (NonNegative n) = all (== primosYhuecosMaximales1 !! n) [primosYhuecosMaximales2 !! n, primosYhuecosMaximales3 !! n] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=12}) prop_primosYhuecosMaximales -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> primosYhuecosMaximales1 !! 10 -- (9551,36) -- (2.63 secs, 7,400,316,112 bytes) -- λ> primosYhuecosMaximales2 !! 10 -- (9551,36) -- (0.01 secs, 7,060,744 bytes) -- λ> primosYhuecosMaximales3 !! 10 -- (9551,36) -- (0.01 secs, 4,000,368 bytes) -- -- λ> primosYhuecosMaximales2 !! 22 -- (17051707,180) -- (7.90 secs, 17,275,407,712 bytes) -- λ> primosYhuecosMaximales3 !! 22 -- (17051707,180) -- (3.78 secs, 8,808,779,096 bytes) |
Basado en el ejercicio Maximal prime gaps de
Programming Praxis.
Otras referencias
El código se encuentra en GitHub.
La indicatriz de Euler (también función φ de Euler) es una función importante en teoría de números. Si n es un entero positivo, entonces φ(n) se define como el número de enteros positivos menores o iguales a n y coprimos con n. Por ejemplo, φ(36) = 12 ya que los números menores o iguales a 36 y coprimos con 36 son doce: 1, 5, 7, 11, 13, 17, 19, 23, 25, 29, 31, y 35.
Definir la función
|
1 |
phi :: Integer -> Integer |
tal que (phi n) es igual a φ(n). Por ejemplo,
|
1 2 3 4 |
phi 36 == 12 map phi [10..20] == [4,10,4,12,6,8,8,16,6,18,8] phi (3^10^5) `mod` (10^9) == 681333334 length (show (phi (10^(10^5)))) == 100000 |
Comprobar con QuickCheck que, para todo n > 0, φ(10^n) tiene n dígitos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
import Data.List (genericLength, group) import Data.Numbers.Primes (primeFactors) import Math.NumberTheory.ArithmeticFunctions (totient) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== phi1 :: Integer -> Integer phi1 n = genericLength [x | x <- [1..n], gcd x n == 1] -- 2ª solución -- =========== phi2 :: Integer -> Integer phi2 n = product [(p-1)*p^(e-1) | (p,e) <- factorizacion n] factorizacion :: Integer -> [(Integer,Integer)] factorizacion n = [(head xs,genericLength xs) | xs <- group (primeFactors n)] -- 3ª solución -- ============= phi3 :: Integer -> Integer phi3 n = product [(x-1) * product xs | (x:xs) <- group (primeFactors n)] -- 4ª solución -- ============= phi4 :: Integer -> Integer phi4 = totient -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_phi :: Positive Integer -> Bool prop_phi (Positive n) = all (== phi1 n) [phi2 n, phi3 n, phi4 n] -- La comprobación es -- λ> quickCheck prop_phi -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> phi1 (2*10^6) -- 800000 -- (2.49 secs, 2,117,853,856 bytes) -- λ> phi2 (2*10^6) -- 800000 -- (0.02 secs, 565,664 bytes) -- -- λ> length (show (phi2 (10^100000))) -- 100000 -- (2.80 secs, 5,110,043,208 bytes) -- λ> length (show (phi3 (10^100000))) -- 100000 -- (4.81 secs, 7,249,353,896 bytes) -- λ> length (show (phi4 (10^100000))) -- 100000 -- (0.78 secs, 1,467,573,768 bytes) -- Verificación de la propiedad -- ============================ -- La propiedad es prop_phi2 :: Positive Integer -> Bool prop_phi2 (Positive n) = genericLength (show (phi4 (10^n))) == n -- La comprobación es -- λ> quickCheck prop_phi2 -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Definir la función
|
1 |
sucSumaCuadradosDigitos :: Integer -> [Integer] |
tal que (sucSumaCuadradosDigitos n) es la sucesión cuyo primer término es n y los restantes se obtienen sumando los cuadrados de los dígitos de su término anterior. Por ejemplo,
|
1 2 3 4 5 6 |
λ> take 20 (sucSumaCuadradosDigitos1 2000) [2000,4,16,37,58,89,145,42,20,4,16,37,58,89,145,42,20,4,16,37] λ> take 20 (sucSumaCuadradosDigitos 1976) [1976,167,86,100,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1] λ> sucSumaCuadradosDigitos 2000 !! (10^9) 20 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
import Test.QuickCheck (Positive (Positive), NonNegative (NonNegative), quickCheck) -- 1ª solución -- =========== sucSumaCuadradosDigitos1 :: Integer -> [Integer] sucSumaCuadradosDigitos1 n = n : [sumaCuadradosDigitos x | x <- sucSumaCuadradosDigitos1 n] -- (sumaCuadradosDigitos n) es la suma de los cuadrados de los dígitos -- de n. Por ejemplo, -- sumaCuadradosDigitos 2016 == 41 sumaCuadradosDigitos :: Integer -> Integer sumaCuadradosDigitos n = sum (map (^2) (digitos n)) -- (digitos n) es la lista de los dígitos de n. Por ejemplo, -- digitos 325 == [3,2,5] digitos :: Integer -> [Integer] digitos n = [read [d] | d <- show n] -- 2ª solución -- =========== sucSumaCuadradosDigitos2 :: Integer -> [Integer] sucSumaCuadradosDigitos2 = iterate sumaCuadradosDigitos -- 3ª solución -- =========== -- A partir de los cálculos con las definiciones anteriores, se observa -- que para todo n (sucSumaCuadradosDigitos n) tiene una parte pura y -- otra periódica. Por ejemplo, para n = 2016, -- λ> take 20 (sucSumaCuadradosDigitos 2016) -- [2016,41,17,50,25,29,85,89,145,42,20,4,16,37,58,89,145,42,20,4] -- la parte pura es -- [2016,41,17,50,25,29,85] -- y la parte periódica es -- [89,145,42,20,4,16,37,58]) sucSumaCuadradosDigitos3 :: Integer -> [Integer] sucSumaCuadradosDigitos3 n = xs ++ cycle ys where (xs,ys) = sucCompactaSumaCuadradosDigitos n -- (sucCompactaSumaCuadradosDigitos n) es el par formado por la parte -- pura y la periódica de (sucSumaCuadradosDigitos n). Por ejemplo, -- λ> sucCompactaSumaCuadradosDigitos 2016 -- ([2016,41,17,50,25,29,85],[89,145,42,20,4,16,37,58]) -- λ> sucCompactaSumaCuadradosDigitos 1976 -- ([1976,167,86,100],[1]) sucCompactaSumaCuadradosDigitos :: Integer -> ([Integer],[Integer]) sucCompactaSumaCuadradosDigitos = partePuraPeriodica . sucSumaCuadradosDigitos1 -- (partePuraPeriodica xs) es el par formado por la parte pura y la -- periódica de xs. Por ejemplo, -- λ> partePuraPeriodica (sucSumaCuadradosDigitos 2016) -- ([2016,41,17,50,25,29,85],[89,145,42,20,4,16,37,58]) -- λ> partePuraPeriodica (sucSumaCuadradosDigitos 1976) -- ([1976,167,86,100],[1]) partePuraPeriodica :: [Integer] -> ([Integer],[Integer]) partePuraPeriodica = aux [] where aux as (b:bs) | b `elem` as = span (/=b) (reverse as) | otherwise = aux (b:as) bs -- 4ª solución -- =========== sucSumaCuadradosDigitos4 :: Integer -> [Integer] sucSumaCuadradosDigitos4 1 = repeat 1 sucSumaCuadradosDigitos4 89 = cycle [89,145,42,20,4,16,37,58] sucSumaCuadradosDigitos4 n = n : sucSumaCuadradosDigitos4 (sumaCuadradosDigitos n) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sucSumaCuadradosDigitos :: Positive Integer -> NonNegative Int -> Bool prop_sucSumaCuadradosDigitos (Positive n) (NonNegative k) = all (== sucSumaCuadradosDigitos1 n !! k) [sucSumaCuadradosDigitos2 n !! k, sucSumaCuadradosDigitos3 n !! k, sucSumaCuadradosDigitos4 n !! k] -- La comprobación es -- λ> quickCheck prop_sucSumaCuadradosDigitos -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> sucSumaCuadradosDigitos1 2000 !! (10^4) -- 20 -- (6.96 secs, 8,049,886,312 bytes) -- λ> sucSumaCuadradosDigitos2 2000 !! (10^4) -- 20 -- (0.08 secs, 91,024,688 bytes) -- λ> sucSumaCuadradosDigitos3 2000 !! (10^4) -- 20 -- (0.01 secs, 995,560 bytes) -- λ> sucSumaCuadradosDigitos4 2000 !! (10^4) -- 20 -- (0.02 secs, 587,040 bytes) -- -- λ> sucSumaCuadradosDigitos2 2000 !! (3*10^5) -- 20 -- (1.96 secs, 2,715,501,416 bytes) -- λ> sucSumaCuadradosDigitos3 2000 !! (3*10^5) -- 20 -- (0.02 secs, 995,872 bytes) -- λ> sucSumaCuadradosDigitos4 2000 !! (3*10^5) -- 20 -- (0.02 secs, 587,352 bytes) -- -- λ> sucSumaCuadradosDigitos3 2000 !! (10^9) -- 20 -- (2.85 secs, 996,016 bytes) -- λ> sucSumaCuadradosDigitos4 2000 !! (10^9) -- 20 -- (2.54 secs, 587,496 bytes) |
El código se encuentra en GitHub.
Un número natural n es una potencia perfecta si existen dos números naturales m > 1 y k > 1 tales que n = m^k. Las primeras potencias perfectas son
|
1 2 |
4 = 2², 8 = 2³, 9 = 3², 16 = 2⁴, 25 = 5², 27 = 3³, 32 = 2⁵, 36 = 6², 49 = 7², 64 = 2⁶, ... |
Definir la sucesión
|
1 |
potenciasPerfectas :: [Integer] |
cuyos términos son las potencias perfectas. Por ejemplo,
|
1 2 |
take 10 potenciasPerfectas == [4,8,9,16,25,27,32,36,49,64] potenciasPerfectas !! 3000 == 7778521 |
Definir el procedimiento
|
1 |
grafica :: Int -> IO () |
tal que (grafica n) es la representación gráfica de las n primeras potencias perfectas. Por ejemplo, para (grafica 30) dibuja

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
import Data.List (group) import Data.Numbers.Primes (primeFactors) import Graphics.Gnuplot.Simple (Attribute (Key, PNG), plotList) import Test.QuickCheck (NonNegative (NonNegative), quickCheck) -- 1ª solución -- =========== potenciasPerfectas1 :: [Integer] potenciasPerfectas1 = filter esPotenciaPerfecta [4..] -- (esPotenciaPerfecta x) se verifica si x es una potencia perfecta. Por -- ejemplo, -- esPotenciaPerfecta 36 == True -- esPotenciaPerfecta 72 == False esPotenciaPerfecta :: Integer -> Bool esPotenciaPerfecta = not . null. potenciasPerfectasDe -- (potenciasPerfectasDe x) es la lista de pares (a,b) tales que -- x = a^b. Por ejemplo, -- potenciasPerfectasDe 64 == [(2,6),(4,3),(8,2)] -- potenciasPerfectasDe 72 == [] potenciasPerfectasDe :: Integer -> [(Integer,Integer)] potenciasPerfectasDe n = [(m,k) | m <- takeWhile (\x -> x*x <= n) [2..] , k <- takeWhile (\x -> m^x <= n) [2..] , m^k == n] -- 2ª solución -- =========== potenciasPerfectas2 :: [Integer] potenciasPerfectas2 = [x | x <- [4..], esPotenciaPerfecta2 x] -- (esPotenciaPerfecta2 x) se verifica si x es una potencia perfecta. Por -- ejemplo, -- esPotenciaPerfecta2 36 == True -- esPotenciaPerfecta2 72 == False esPotenciaPerfecta2 :: Integer -> Bool esPotenciaPerfecta2 x = mcd (exponentes x) > 1 -- (exponentes x) es la lista de los exponentes de l factorización prima -- de x. Por ejemplos, -- exponentes 36 == [2,2] -- exponentes 72 == [3,2] exponentes :: Integer -> [Int] exponentes x = [length ys | ys <- group (primeFactors x)] -- (mcd xs) es el máximo común divisor de la lista xs. Por ejemplo, -- mcd [4,6,10] == 2 -- mcd [4,5,10] == 1 mcd :: [Int] -> Int mcd = foldl1 gcd -- 3ª solución -- =========== potenciasPerfectas3 :: [Integer] potenciasPerfectas3 = mezclaTodas potencias -- potencias es la lista las listas de potencias de todos los números -- mayores que 1 con exponentes mayores que 1. Por ejemplo, -- λ> map (take 3) (take 4 potencias) -- [[4,8,16],[9,27,81],[16,64,256],[25,125,625]] potencias:: [[Integer]] potencias = [[n^k | k <- [2..]] | n <- [2..]] -- (mezclaTodas xss) es la mezcla ordenada sin repeticiones de las -- listas ordenadas xss. Por ejemplo, -- take 7 (mezclaTodas potencias) == [4,8,9,16,25,27,32] mezclaTodas :: Ord a => [[a]] -> [a] mezclaTodas = foldr1 xmezcla where xmezcla (x:xs) ys = x : mezcla xs ys -- (mezcla xs ys) es la mezcla ordenada sin repeticiones de las -- listas ordenadas xs e ys. Por ejemplo, -- take 7 (mezcla [2,5..] [4,6..]) == [2,4,5,6,8,10,11] mezcla :: Ord a => [a] -> [a] -> [a] mezcla (x:xs) (y:ys) | x < y = x : mezcla xs (y:ys) | x == y = x : mezcla xs ys | x > y = y : mezcla (x:xs) ys -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_potenciasPerfectas :: NonNegative Int -> Bool prop_potenciasPerfectas (NonNegative n) = all (== potenciasPerfectas1 !! n) [potenciasPerfectas2 !! n, potenciasPerfectas3 !! n] -- La comprobación es -- λ> quickCheck prop_potenciasPerfectas -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> potenciasPerfectas1 !! 200 -- 28224 -- (10.56 secs, 8,434,647,368 bytes) -- λ> potenciasPerfectas2 !! 200 -- 28224 -- (0.36 secs, 825,040,416 bytes) -- λ> potenciasPerfectas3 !! 200 -- 28224 -- (0.05 secs, 7,474,280 bytes) -- -- λ> potenciasPerfectas2 !! 500 -- 191844 -- (4.16 secs, 9,899,367,112 bytes) -- λ> potenciasPerfectas3 !! 500 -- 191844 -- (0.09 secs, 51,275,464 bytes) -- En lo que sigue se usa la 3ª solución potenciasPerfectas :: [Integer] potenciasPerfectas = potenciasPerfectas3 -- Representación gráfica -- ====================== grafica :: Int -> IO () grafica n = plotList [ Key Nothing , PNG "Potencias_perfectas.png" ] (take n potenciasPerfectas) |
El código se encuentra en GitHub.
Las primeras sumas alternas de los factoriales son números primos; en efecto,
|
1 2 3 4 5 6 |
3! - 2! + 1! = 5 4! - 3! + 2! - 1! = 19 5! - 4! + 3! - 2! + 1! = 101 6! - 5! + 4! - 3! + 2! - 1! = 619 7! - 6! + 5! - 4! + 3! - 2! + 1! = 4421 8! - 7! + 6! - 5! + 4! - 3! + 2! - 1! = 35899 |
son primos, pero
|
1 |
9! - 8! + 7! - 6! + 5! - 4! + 3! - 2! + 1! = 326981 |
no es primo.
Definir las funciones
|
1 2 3 |
sumaAlterna :: Integer -> Integer sumasAlternas :: [Integer] conSumaAlternaPrima :: [Integer] |
tales que
|
1 2 3 4 5 6 7 8 |
sumaAlterna 3 == 5 sumaAlterna 4 == 19 sumaAlterna 5 == 101 sumaAlterna 6 == 619 sumaAlterna 7 == 4421 sumaAlterna 8 == 35899 sumaAlterna 9 == 326981 sumaAlterna (5*10^4) `mod` (10^6) == 577019 |
|
1 2 |
λ> take 10 sumasAlternas1 [0,1,1,5,19,101,619,4421,35899,326981] |
|
1 2 |
λ> take 8 conSumaAlternaPrima [3,4,5,6,7,8,10,15] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 |
import Data.List (genericTake) import Data.Numbers.Primes (isPrime) import Test.QuickCheck -- 1ª definición de sumaAlterna -- ============================ sumaAlterna1 :: Integer -> Integer sumaAlterna1 1 = 1 sumaAlterna1 n = factorial n - sumaAlterna1 (n-1) factorial :: Integer -> Integer factorial n = product [1..n] -- 2ª definición de sumaAlterna -- ============================ sumaAlterna2 :: Integer -> Integer sumaAlterna2 n = sum (genericTake n (zipWith (*) signos (tail factoriales))) where signos | odd n = concat (repeat [1,-1]) | otherwise = concat (repeat [-1,1]) -- factoriales es la lista de los factoriales. Por ejemplo, -- take 7 factoriales == [1,1,2,6,24,120,720] factoriales :: [Integer] factoriales = 1 : scanl1 (*) [1..] -- 3ª definición de sumaAlterna -- ============================ sumaAlterna3 :: Integer -> Integer sumaAlterna3 n = sum (genericTake n (zipWith (*) signos (tail factoriales))) where signos | odd n = cycle [1,-1] | otherwise = cycle [-1,1] -- 3ª definición de sumaAlterna -- ============================ sumaAlterna4 :: Integer -> Integer sumaAlterna4 n = foldl (flip (-)) 0 (scanl1 (*) [1..n]) -- Comprobación de equivalencia de sumaAlterna -- =========================================== -- La propiedad es prop_sumaAlterna :: Positive Integer -> Bool prop_sumaAlterna (Positive n) = all (== sumaAlterna1 n) [sumaAlterna2 n, sumaAlterna3 n, sumaAlterna4 n] -- La comprobación es -- λ> quickCheck prop_sumaAlterna -- +++ OK, passed 100 tests. -- Comparación de eficiencia de sumaAlterna -- ======================================== -- La comparación es -- λ> sumaAlterna1 4000 `mod` (10^6) -- 577019 -- (6.21 secs, 16,154,113,192 bytes) -- λ> sumaAlterna2 4000 `mod` (10^6) -- 577019 -- (0.01 secs, 24,844,664 bytes) -- -- λ> sumaAlterna2 (5*10^4) `mod` (10^6) -- 577019 -- (1.81 secs, 4,729,583,864 bytes) -- λ> sumaAlterna3 (5*10^4) `mod` (10^6) -- 577019 -- (0.89 secs, 4,725,983,928 bytes) -- λ> sumaAlterna4 (5*10^4) `mod` (10^6) -- 577019 -- (0.70 secs, 4,710,770,592 bytes) -- En lo que sigue se usa la 3ª definición sumaAlterna :: Integer -> Integer sumaAlterna = sumaAlterna3 -- 1ª definición de sumasAlternas -- ============================== sumasAlternas1 :: [Integer] sumasAlternas1 = map sumaAlterna [0..] -- 2ª definición de sumasAlternas -- ============================== sumasAlternas2 :: [Integer] sumasAlternas2 = 0 : zipWith (-) (tail factoriales) sumasAlternas2 -- 3ª definición de sumasAlternas -- ============================== sumasAlternas3 :: [Integer] sumasAlternas3 = scanl (flip (-)) 0 $ scanl1 (*) [1..] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_sumasAlternas :: NonNegative Int -> Bool prop_sumasAlternas (NonNegative n) = all (== sumasAlternas1 !! n) [sumasAlternas2 !! n, sumasAlternas3 !! n] -- La comprobación es -- λ> quickCheck prop_sumasAlternas -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> length (show (sumasAlternas1 !! (5*10^4))) -- 213237 -- (4.90 secs, 4,731,620,600 bytes) -- λ> length (show (sumasAlternas2 !! (5*10^4))) -- 213237 -- (2.39 secs, 4,726,820,456 bytes) -- λ> length (show (sumasAlternas3 !! (5*10^4))) -- 213237 -- (1.78 secs, 4,726,820,280 bytes) -- 1ª definición de conSumaAlternaPrima -- ==================================== conSumaAlternaPrima1 :: [Integer] conSumaAlternaPrima1 = [n | n <- [0..], isPrime (sumaAlterna n)] -- 2ª definición de conSumaAlternaPrima -- ==================================== conSumaAlternaPrima2 :: [Integer] conSumaAlternaPrima2 = [x | (x,y) <- zip [0..] sumasAlternas2, isPrime y] -- 3ª definición de conSumaAlternaPrima -- ==================================== conSumaAlternaPrima3 :: [Integer] conSumaAlternaPrima3 = filter (isPrime . sumaAlterna) [0..] -- Comprobación de equivalencia de conSumaAlternaPrima -- =================================================== -- La propiedad es prop_conSumaAlternaPrima :: NonNegative Int -> Bool prop_conSumaAlternaPrima (NonNegative n) = all (== conSumaAlternaPrima1 !! n) [conSumaAlternaPrima2 !! n, conSumaAlternaPrima3 !! n] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=5}) prop_conSumaAlternaPrima -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Un primo con cubo es un número primo p para el que existe algún entero positivo n tal que la expresión n^3 + n^2p es un cubo perfecto. Por ejemplo, 19 es un primo con cubo ya que 8^3 + 8^2×19 = 12^3.
Definir la sucesión
|
1 |
primosConCubos :: [Integer] |
tal que sus elementos son los primos con cubo. Por ejemplo,
|
1 2 3 4 |
λ> take 6 primosConCubos [7,19,37,61,127,271] λ> length (takeWhile (< 1000000) primosConCubos) 173 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
import Data.Numbers.Primes (isPrime) import Test.QuickCheck (NonNegative (NonNegative), maxSize, quickCheckWith, stdArgs) -- 1ª solución -- =========== primosConCubos1 :: [Integer] primosConCubos1 = [p | x <- [1..], n <- [1..x], (x^3 - n^3) `mod` (n^2) == 0, let p = (x^3 - n^3) `div` (n^2), isPrime p] -- 2ª solución -- =========== -- Para analizar la respuesta, en esta solución se calculan los pares -- (p,n) tales que p es un primo con cubo y n es un número positivo tal -- que n^3 + n^2p es un cubo primosConCubos2' :: [(Integer,Integer)] primosConCubos2' = [(p,n) | x <- [1..], n <- [1..x], (x^3 - n^3) `mod` (n^2) == 0, let p = (x^3 - n^3) `div` (n^2), isPrime p] -- El cálculo es -- λ> take 7 primosConCubos2 -- [(7,1),(19,8),(37,27),(61,64),(127,216),(271,729),(331,1000)] -- Se observa que la sucesión de los segundos elementos [1,8,27,64,...] -- es la de los cubos y que los primeros elementos se obtienen restando -- los segundos elementos consecutivos; es decir, -- 7 = 8 - 1 = 2^3 - 1^3 -- 19 = 27 - 8 = 3^3 - 2^3 -- 37 = 64 - 27 = 4^3 - 3^3 -- Continuando el patrón, -- 61 = 5^3 - 4^3 = 125 - 64 -- 91 = 6^3 - 5^3 = 216 - 125 -- 127 = 7^3 - 6^3 = 343 - 216 -- 271 = 10^3 - 9^3 = 1000 - 729 -- 331 = 11^3 -10^3 = 1331 - 1000 -- Por tanto, los primos con cubos son diferencias de dos cubos -- consecutivos; es decir, coinciden con los números cubanos del -- ejercicio anterior. A partir de la conjetura se obtienen las -- siguientes definiciones -- Basado en las anteriores observaciones se obtiene la siguiente -- definición primosConCubos2 :: [Integer] primosConCubos2 = filter isPrime [(x+1)^3 - x^3 | x <- [1..]] -- 3ª definición -- ============= primosConCubos3 :: [Integer] primosConCubos3 = filter isPrime diferenciasCubosConsecutivos diferenciasCubosConsecutivos :: [Integer] diferenciasCubosConsecutivos = zipWith (-) (tail cubos) cubos cubos :: [Integer] cubos = map (^3) [0..] -- 4ª solución -- =========== -- Simplificando la expresión (x+1)^3 - x^3 se obtiene 3*x^2+ 3*x + 1, -- con lo que la 3ª definición se reduce a primosConCubos4 :: [Integer] primosConCubos4 = [p | x <- [1..], let p = 3*x^2+ 3*x + 1, isPrime p] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_primosConCubos :: NonNegative Int -> Bool prop_primosConCubos (NonNegative n) = all (== primosConCubos1 !! n) [primosConCubos2 !! n, primosConCubos3 !! n, primosConCubos4 !! n] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=10}) prop_primosConCubos -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> primosConCubos1 !! 6 -- 331 -- (1.15 secs, 1,105,612,336 bytes) -- λ> primosConCubos1 !! 7 -- 397 -- (1.96 secs, 1,909,369,592 bytes) -- λ> primosConCubos2 !! 7 -- 397 -- -- (0.01 secs, 648,840 bytes) -- λ> primosConCubos2 !! (10^3) -- 65580901 -- (0.53 secs, 1,726,837,688 bytes) -- λ> primosConCubos3 !! (10^3) -- 65580901 -- (0.49 secs, 1,724,258,632 bytes) -- λ> primosConCubos4 !! (10^3) -- 65580901 -- (0.47 secs, 1,724,833,992 bytes) -- Demostración de la conjetura -- ============================ -- Vamos a demostrar que los primos con cubos son diferencias de dos -- cubos consecutivos. -- -- Sea p un primo con cubo. Por la definición, existe un entero -- positivo n tal que n³ + n²p es un cubo. -- -- Lema 1: Los números n y p son coprimos (es decir, mcd(n,p) = 1). -- Dem.: En caso contrario, puesto que p es primo, existe un a tal que -- n = ap. Luego n³ + n²p = (a³+a²)p³ es un cubo y, por tanto, -- a³+a² es un cubo lo que es imposible ya que el siguiente cubo de -- a³ es a³+3a²+3a+1. -- -- Lema 2: Los números n² y n+p son coprimos. -- Dem.: Sea k = mcd(n^2,n+p). Por k divide n², luego k divide a n; -- además, k divide a n+p y (usando el lema 1 y el ser p primo), se -- tiene que k = 1. -- -- Puesto que n³+n²p = n²(n+p) es un cubo, usando el lema 2, se tiene -- que n² y n+p son cubos y, por serlo n², n también es un cubo. Es -- decir, existen enteros positivos x e y tales que n = x³ y -- n+p = y³. Por tanto, p = y³-x³. Sea k = y-x. Se tiene que k = 1 ya -- que -- p = y³-x³ -- = (n+k)³-n³ -- = 3k+3k²+k³ -- no es primo para k > 1. -- -- Por consiguiente, p = (x+1)³-x³. |
El código se encuentra en GitHub.
Un primo cubano es un número primo que se puede escribir como diferencia de dos cubos consecutivos. Por ejemplo, el 61 es un primo cubano porque es primo y 61 = 5³-4³.
Definir la sucesión
|
1 |
cubanos :: [Integer] |
tal que sus elementos son los números cubanos. Por ejemplo,
|
1 2 |
λ> take 15 cubanos [7,19,37,61,127,271,331,397,547,631,919,1657,1801,1951,2269] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import Data.Numbers.Primes (isPrime) import Test.QuickCheck -- 1ª solución -- =========== cubanos1 :: [Integer] cubanos1 = filter isPrime (zipWith (-) (tail cubos) cubos) -- cubos es la lista de los cubos. Por ejemplo, -- λ> take 10 cubos -- [1,8,27,64,125,216,343,512,729,1000] cubos :: [Integer] cubos = map (^3) [1..] -- 2ª solución -- =========== cubanos2 :: [Integer] cubanos2 = filter isPrime [(x+1)^3 - x^3 | x <- [1..]] -- 3ª solución -- =========== cubanos3 :: [Integer] cubanos3 = filter isPrime [3*x^2 + 3*x + 1 | x <- [1..]] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_cubanos :: NonNegative Int -> Bool prop_cubanos (NonNegative n) = all (== cubanos1 !! n) [cubanos2 !! n, cubanos3 !! n] -- La comprobación es -- λ> quickCheck prop_cubanos -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> cubanos1 !! 3000 -- 795066361 -- (4.21 secs, 16,953,612,192 bytes) -- λ> cubanos2 !! 3000 -- 795066361 -- (4.27 secs, 16,962,597,288 bytes) -- λ> cubanos3 !! 3000 -- 795066361 -- (4.29 secs, 16,956,085,672 bytes) |
El código se encuentra en GitHub.
La clausura transitiva de una relación binaria R es la relación transitiva que contiene a R. Se puede calcular
usando la composición de relaciones. Veamos un ejemplo, en el que (R ∘ S) representa la composición de R y S: sea
|
1 |
R = [(1,2),(2,5),(5,6)] |
la relación R no es transitiva ya que (1,2) y (1,5) pertenecen a R pero (1,5) no pertenece; sea
|
1 2 |
R1 = R ∪ (R ∘ R) = [(1,2),(2,5),(5,6),(1,5),(2,6)] |
la relación R1 tampoco es transitiva ya que (1,2) y (2,6) pertenecen a R pero (1,6) no pertenece; sea
|
1 2 |
R2 = R1 ∪ (R1 ∘ R1) = [(1,2),(2,5),(5,6),(1,5),(2,6),(1,6)] |
La relación R2 es transitiva y contiene a R. Además, R2 es la clausura transitiva de R.
Definir la función
|
1 |
clausuraTransitiva :: Ord a => [(a,a)] -> [(a,a)] |
tal que (clausuraTransitiva r) es la clausura transitiva de r; es decir, la menor relación transitiva que contiene a r. Por ejemplo,
|
1 2 3 4 5 6 |
λ> clausuraTransitiva [(1,2),(2,5),(5,6)] [(1,2),(2,5),(5,6),(1,5),(2,6),(1,6)] λ> clausuraTransitiva [(1,2),(2,5),(5,6),(6,3)] [(1,2),(2,5),(5,6),(6,3),(1,5),(2,6),(5,3),(1,6),(2,3),(1,3)] λ> length (clausuraTransitiva [(n,n+1) | n <- [1..100]]) 5050 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 |
import Data.List (union, nub, sort) import Data.Maybe (mapMaybe) import qualified Data.Map as M (Map, assocs, empty, insertWith, lookup, map) import Test.QuickCheck (quickCheck) -- 1ª solución -- =========== clausuraTransitiva1 :: Ord a => [(a,a)] -> [(a,a)] clausuraTransitiva1 r | transitiva r = r | otherwise = clausuraTransitiva1 r1 where r1 = r `union` composicion r r -- (transitiva r) se verifica si la relación r es transitiva. Por -- ejemplo, -- transitiva [(1,1),(1,3),(3,1),(3,3),(5,5)] == True -- transitiva [(1,1),(1,3),(3,1),(5,5)] == False transitiva :: Ord a => [(a,a)] -> Bool transitiva r = subconjunto (composicion r r) r -- (composicion r s) es la composición de las relaciones binarias r y -- s. Por ejemplo, -- λ> composicion [(1,2)] [(2,3),(2,4)] -- [(1,3),(1,4)] -- λ> composicion [(1,2),(5,2)] [(2,3),(2,4)] -- [(1,3),(1,4),(5,3),(5,4)] -- λ> composicion [(1,2),(1,4),(1,5)] [(2,3),(4,3)] -- [(1,3)] composicion :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion r s = nub [(x,y) | (x,u) <- r, (v,y) <- s, u == v] -- (subconjunto xs ys) se verifica si xs es un subconjunto de xs. Por -- ejemplo, -- subconjunto [1,3] [3,1,5] == True -- subconjunto [3,1,5] [1,3] == False subconjunto :: Ord a => [a] -> [a] -> Bool subconjunto xs ys = all (`elem` ys) xs -- 2ª solución -- ============= clausuraTransitiva2 :: Ord a => [(a,a)] -> [(a,a)] clausuraTransitiva2 r | r1 == r = r | otherwise = clausuraTransitiva2 r1 where r1 = r `union` composicion r r -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_clausuraTransitiva :: [(Int,Int)] -> Bool prop_clausuraTransitiva r = all (== sort (clausuraTransitiva1 r)) [sort (clausuraTransitiva2 r), sort (clausuraTransitiva3 r)] -- La comprobación es -- λ> quickCheck prop_clausuraTransitiva -- +++ OK, passed 100 tests. -- 3ª solución -- =========== clausuraTransitiva3 :: Ord a => [(a,a)] -> [(a,a)] clausuraTransitiva3 r | transitiva3 r = r | otherwise = clausuraTransitiva3 r1 where r1 = r `union` composicion3 r r transitiva3 :: Ord a => [(a,a)] -> Bool transitiva3 r = subconjunto (composicion3 r r) r composicion3 :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion3 r s = relAlista (composicionRel (listaArel r) (listaArel s)) -- Una relación se puede representar por un diccionario donde las claves -- son los elementos y los valores son las listas de los elementos con -- los que se relaciona. type Rel a = M.Map a [a] -- (listaArel xys) es la relación correspondiente a la lista de pares -- xys. Por ejemplo. -- λ> listaArel [(1,1),(1,2),(1,3),(1,6),(2,2),(2,6),(3,3),(3,6),(6,6)] -- fromList [(1,[1,2,3,6]),(2,[2,6]),(3,[3,6]),(6,[6])] listaArel :: Ord a => [(a,a)] -> Rel a listaArel [] = M.empty listaArel ((x,y):xys) = M.insertWith (++) x [y] (listaArel xys) -- (composicionRel r s) es la composición de las relaciones r y s. Por -- ejemplo, -- λ> r = listaArel [(1,2),(5,2)] -- λ> s = listaArel [(2,3),(2,4)] -- λ> composicionRel r s -- fromList [(1,[3,4]),(5,[3,4])] composicionRel :: Ord a => Rel a -> Rel a -> Rel a composicionRel r s = M.map f r where f xs = concat (mapMaybe (`M.lookup` s) xs) -- (relAlista r) es la lista de pares correspondientes a la relación -- r. Por ejemplo, -- λ> relAlista (M.fromList [(1,[3,4]),(5,[3,4])]) -- [(1,3),(1,4),(5,3),(5,4)] relAlista :: Ord a => Rel a -> [(a,a)] relAlista r = nub [(x,y) | (x,ys) <- M.assocs r, y <- ys] -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> length (clausuraTransitiva1 [(n,n+1) | n <- [1..60]]) -- 1830 -- (2.15 secs, 453,533,992 bytes) -- λ> length (clausuraTransitiva2 [(n,n+1) | n <- [1..60]]) -- 1830 -- (2.23 secs, 558,571,904 bytes) -- λ> length (clausuraTransitiva3 [(n,n+1) | n <- [1..60]]) -- 1830 -- (0.25 secs, 207,168,552 bytes) |
El código se encuentra en GitHub.
Una relación binaria R sobre un conjunto A es transitiva cuando se cumple que siempre que un elemento se relaciona con otro y éste último con un tercero, entonces el primero se relaciona con el tercero.
Definir la función
|
1 |
transitiva :: Ord a => [(a,a)] -> Bool |
tal que (transitiva r) se verifica si la relación r es transitiva. Por ejemplo,
|
1 2 3 |
transitiva [(1,1),(1,3),(3,1),(3,3),(5,5)] == True transitiva [(1,1),(1,3),(3,1),(5,5)] == False transitiva [(n,n) | n <- [1..10^4]] == True |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 |
import Data.List (nub) import Data.Maybe (mapMaybe) import qualified Data.Map as M (Map, assocs, empty, insertWith, lookup, map) import Test.QuickCheck (maxSize, quickCheckWith, stdArgs) -- 1ª solución -- =========== transitiva1 :: Ord a => [(a,a)] -> Bool transitiva1 r = and [(x,y) `elem` r | (x,u) <- r, (v,y) <- r, u == v] -- 2ª solución -- =========== transitiva2 :: Ord a => [(a,a)] -> Bool transitiva2 r = all (`elem` r) [(x,y) | (x,u) <- r, (v,y) <- r, u == v] -- 3ª solución -- =========== transitiva3 :: Ord a => [(a,a)] -> Bool transitiva3 r = subconjunto (composicion r r) r -- (subconjunto xs ys) se verifica si xs es un subconjunto de xs. Por -- ejemplo, -- subconjunto [1,3] [3,1,5] == True -- subconjunto [3,1,5] [1,3] == False subconjunto :: Ord a => [a] -> [a] -> Bool subconjunto xs ys = all (`elem`ys) xs -- (composicion r s) es la composición de las relaciones binarias r y -- s. Por ejemplo, -- λ> composicion [(1,2)] [(2,3),(2,4)] -- [(1,3),(1,4)] -- λ> composicion [(1,2),(5,2)] [(2,3),(2,4)] -- [(1,3),(1,4),(5,3),(5,4)] -- λ> composicion [(1,2),(1,4),(1,5)] [(2,3),(4,3)] -- [(1,3)] composicion :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion r s = nub [(x,y) | (x,u) <- r, (v,y) <- s, u == v] -- 3ª solución -- =========== transitiva4 :: Ord a => [(a,a)] -> Bool transitiva4 r = subconjunto (composicion4 r r) r composicion4 :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion4 r s = relAlista (composicionRel (listaArel r) (listaArel s)) -- Una relación se puede representar por un diccionario donde las claves -- son los elementos y los valores son las listas de los elementos con -- los que se relaciona. type Rel a = M.Map a [a] -- (listaArel xys) es la relación correspondiente a la lista de pares -- xys. Por ejemplo. -- λ> listaArel [(1,1),(1,2),(1,3),(1,6),(2,2),(2,6),(3,3),(3,6),(6,6)] -- fromList [(1,[1,2,3,6]),(2,[2,6]),(3,[3,6]),(6,[6])] listaArel :: Ord a => [(a,a)] -> Rel a listaArel [] = M.empty listaArel ((x,y):xys) = M.insertWith (++) x [y] (listaArel xys) -- (composicionRel r s) es la composición de las relaciones r y s. Por -- ejemplo, -- λ> r = listaArel [(1,2),(5,2)] -- λ> s = listaArel [(2,3),(2,4)] -- λ> composicionRel r s -- fromList [(1,[3,4]),(5,[3,4])] composicionRel :: Ord a => Rel a -> Rel a -> Rel a composicionRel r s = M.map f r where f xs = concat (mapMaybe (`M.lookup` s) xs) -- (relAlista r) es la lista de pares correspondientes a la relación -- r. Por ejemplo, -- λ> relAlista (M.fromList [(1,[3,4]),(5,[3,4])]) -- [(1,3),(1,4),(5,3),(5,4)] relAlista :: Ord a => Rel a -> [(a,a)] relAlista r = nub [(x,y) | (x,ys) <- M.assocs r, y <- ys] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_transitiva :: [(Int,Int)] -> Bool prop_transitiva r = all (== transitiva1 r) [transitiva2 r, transitiva3 r, transitiva4 r] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=7}) prop_transitiva -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> transitiva1 [(n,n) | n <- [1..5*10^3]] -- True -- (4.27 secs, 1,403,139,032 bytes) -- λ> transitiva2 [(n,n) | n <- [1..5*10^3]] -- True -- (4.24 secs, 1,402,739,056 bytes) -- λ> transitiva3 [(n,n) | n <- [1..5*10^3]] -- True -- (4.41 secs, 1,403,219,880 bytes) -- λ> transitiva4 [(n,n) | n <- [1..5*10^3]] -- True -- (0.46 secs, 16,206,624 bytes) |
El código se encuentra en GitHub.
Las relaciones binarias en un conjunto A se pueden representar mediante conjuntos de pares de elementos de A. Por ejemplo, la relación de divisibilidad en el conjunto {1,2,3,6} se representa por
|
1 |
[(1,1),(1,2),(1,3),(1,6),(2,2),(2,6),(3,3),(3,6),(6,6)] |
La composición de dos relaciones binarias R y S en el conjunto A es la relación binaria formada por los pares (x,y) para los que existe un z tal que (x,z) ∈ R y (z,y) ∈ S.
Definir la función
|
1 |
composicion :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] |
tal que (composicion r s) es la composición de las relaciones binarias r y s. Por ejemplo,
|
1 2 3 4 5 6 |
λ> composicion [(1,2)] [(2,3),(2,4)] [(1,3),(1,4)] λ> composicion [(1,2),(5,2)] [(2,3),(2,4)] [(1,3),(1,4),(5,3),(5,4)] λ> composicion [(1,2),(1,4),(1,5)] [(2,3),(4,3)] [(1,3)] |
Nota: Se supone que las relaciones binarias son listas sin elementos repetidos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
import Data.List (nub, sort) import Data.Maybe (mapMaybe) import qualified Data.Set.Monad as S (Set, fromList, toList) import qualified Data.Map as M (Map, assocs, empty, insertWith, lookup, map) import Test.QuickCheck (quickCheck) -- 1ª solución -- =========== composicion1 :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion1 r s = nub [(x,y) | (x,u) <- r, (v,y) <- s, u == v] -- 2ª solución -- =========== composicion2 :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion2 r s = S.toList (composicionS (S.fromList r) (S.fromList s)) composicionS :: Ord a => S.Set (a,a) -> S.Set (a,a) -> S.Set (a,a) composicionS r s = [(x,y) | (x,u) <- r, (v,y) <- s, u == v] -- 3ª solución -- =========== composicion3 :: Ord a => [(a,a)] -> [(a,a)] -> [(a,a)] composicion3 r s = relAlista (composicionRel (listaArel r) (listaArel s)) -- Una relación se puede representar por un diccionario donde las claves -- son los elementos y los valores son las listas de los elementos con -- los que se relaciona. type Rel a = M.Map a [a] -- (listaArel xys) es la relación correspondiente a la lista de pares -- xys. Por ejemplo. -- λ> listaArel [(1,1),(1,2),(1,3),(1,6),(2,2),(2,6),(3,3),(3,6),(6,6)] -- fromList [(1,[1,2,3,6]),(2,[2,6]),(3,[3,6]),(6,[6])] listaArel :: Ord a => [(a,a)] -> Rel a listaArel [] = M.empty listaArel ((x,y):xys) = M.insertWith (++) x [y] (listaArel xys) -- (composicionRel r s) es la composición de las relaciones r y s. Por -- ejemplo, -- λ> r = listaArel [(1,2),(5,2)] -- λ> s = listaArel [(2,3),(2,4)] -- λ> composicionRel r s -- fromList [(1,[3,4]),(5,[3,4])] composicionRel :: Ord a => Rel a -> Rel a -> Rel a composicionRel r s = M.map f r where f xs = concat (mapMaybe (`M.lookup` s) xs) -- (relAlista r) es la lista de pares correspondientes a la relación -- r. Por ejemplo, -- λ> relAlista (M.fromList [(1,[3,4]),(5,[3,4])]) -- [(1,3),(1,4),(5,3),(5,4)] relAlista :: Ord a => Rel a -> [(a,a)] relAlista r = nub [(x,y) | (x,ys) <- M.assocs r, y <- ys] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_composicion :: [(Int,Int)] -> [(Int,Int)] -> Bool prop_composicion r s = all (== sort (composicion1 r' s')) [sort (composicion2 r' s'), sort (composicion3 r' s')] where r' = nub r s' = nub s -- La comprobación es -- λ> quickCheck prop_composicion -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> length (composicion1 [(n,n+1) | n <- [1..2000]] [(n,n+1) | n <- [1..2000]]) -- 1999 -- (1.54 secs, 770,410,352 bytes) -- λ> length (composicion2 [(n,n+1) | n <- [1..2000]] [(n,n+1) | n <- [1..2000]]) -- 1999 -- (1.66 secs, 1,348,948,096 bytes) -- λ> length (composicion3 [(n,n+1) | n <- [1..2000]] [(n,n+1) | n <- [1..2000]]) -- 1999 -- (0.07 secs, 6,960,552 bytes) -- -- λ> r100 = [(n,k) | n <- [1..100], k <- [1..n]] -- λ> length (composicion1 r100 r100) -- 5050 -- (9.91 secs, 4,946,556,944 bytes) -- λ> length (composicion2 r100 r100) -- 5050 -- (13.59 secs, 15,241,357,536 bytes) -- λ> length (composicion3 r100 r100) -- 5050 -- (0.35 secs, 52,015,544 bytes) |
El código se encuentra en GitHub.
Definir la función
|
1 |
numeroParticiones :: Int -> Int -> Int |
tal que (numeroParticiones n k) es el número de particiones de conjunto de n elementos en k subconjuntos disjuntos. Por ejemplo,
|
1 2 3 4 5 6 |
numeroParticiones 3 2 == 3 numeroParticiones 3 3 == 1 numeroParticiones 4 3 == 6 numeroParticiones 4 1 == 1 numeroParticiones 4 4 == 1 numeroParticiones 91 89 == 8139495 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
import Data.Array (Array, (!), array) import Test.QuickCheck (Positive (Positive), quickCheckWith) -- 1ª solución -- =========== numeroParticiones1 :: Int -> Int -> Int numeroParticiones1 n k = length (particiones1 [1..n] k) particiones1 :: [a] -> Int -> [[[a]]] particiones1 [] _ = [] particiones1 _ 0 = [] particiones1 xs 1 = [[xs]] particiones1 (x:xs) k = [[x]:ys | ys <- particiones1 xs (k-1)] ++ concat [inserta x ys | ys <- particiones1 xs k] -- (inserta x yss) es la lista obtenida insertando x en cada uno de los -- conjuntos de yss. Por ejemplo, -- inserta 4 [[3],[2,5]] == [[[4,3],[2,5]],[[3],[4,2,5]]] inserta :: a -> [[a]] -> [[[a]]] inserta _ [] = [] inserta x (ys:yss) = ((x:ys):yss) : [ys:zss | zss <- inserta x yss] -- 2ª solución -- =========== numeroParticiones2 :: Int -> Int -> Int numeroParticiones2 0 _ = 0 numeroParticiones2 _ 0 = 0 numeroParticiones2 _ 1 = 1 numeroParticiones2 n k = k * numeroParticiones2 (n-1) k + numeroParticiones2 (n-1) (k-1) -- 3ª solución -- =========== numeroParticiones3 :: Int -> Int -> Int numeroParticiones3 n k = matrizNumeroParticiones n k ! (n,k) matrizNumeroParticiones :: Int -> Int -> Array (Int,Int) Int matrizNumeroParticiones n k = q where q = array ((0,0),(n,k)) [((i,j), f i j) | i <- [0..n], j <- [0..k]] f _ 0 = 0 f 0 _ = 0 f _ 1 = 1 f i j | i == j = 1 | otherwise = j * f (i-1) j + f (i-1) (j-1) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_numeroParticiones :: Positive Int -> Positive Int -> Bool prop_numeroParticiones (Positive n) (Positive k) = all (== numeroParticiones1 n k) [numeroParticiones2 n k, numeroParticiones3 n k] -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=10}) prop_numeroParticiones -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> numeroParticiones1 12 6 -- 1323652 -- (1.22 secs, 1,152,945,608 bytes) -- λ> numeroParticiones2 12 6 -- 1323652 -- (0.00 secs, 1,283,152 bytes) -- λ> numeroParticiones3 12 6 -- 1323652 -- (0.01 secs, 1,155,864 bytes) -- -- λ> numeroParticiones2 21 19 -- 19285 -- (2.04 secs, 990,274,976 bytes) -- λ> numeroParticiones3 21 19 -- 19285 -- (0.00 secs, 940,736 bytes) |
El código se encuentra en GitHub.
Definir la función
|
1 |
particiones :: [a] -> Int -> [[[a]]] |
tal que (particiones xs k) es la lista de las particiones de xs en k subconjuntos disjuntos. Por ejemplo,
|
1 2 3 4 5 6 7 8 9 10 11 |
λ> particiones [2,3,6] 2 [[[2],[3,6]],[[2,3],[6]],[[3],[2,6]]] λ> particiones [2,3,6] 3 [[[2],[3],[6]]] λ> particiones [4,2,3,6] 3 [[[4],[2],[3,6]],[[4],[2,3],[6]],[[4],[3],[2,6]], [[4,2],[3],[6]],[[2],[4,3],[6]],[[2],[3],[4,6]]] λ> particiones [4,2,3,6] 1 [[[4,2,3,6]]] λ> particiones [4,2,3,6] 4 [[[4],[2],[3],[6]]] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
import Data.List (nub, sort) import Data.Array (Array, (!), array, listArray) import Test.QuickCheck (Positive (Positive), quickCheckWith) -- 1ª solución -- =========== particiones1 :: [a] -> Int -> [[[a]]] particiones1 [] _ = [] particiones1 _ 0 = [] particiones1 xs 1 = [[xs]] particiones1 (x:xs) k = [[x]:ys | ys <- particiones1 xs (k-1)] ++ concat [inserta x ys | ys <- particiones1 xs k] -- (inserta x yss) es la lista obtenida insertando x en cada uno de los -- conjuntos de yss. Por ejemplo, -- inserta 4 [[3],[2,5]] == [[[4,3],[2,5]],[[3],[4,2,5]]] inserta :: a -> [[a]] -> [[[a]]] inserta _ [] = [] inserta x (ys:yss) = ((x:ys):yss) : [ys:zss | zss <- inserta x yss] -- 2ª solución -- =========== particiones2 :: [a] -> Int -> [[[a]]] particiones2 [] _ = [] particiones2 _ 0 = [] particiones2 xs 1 = [[xs]] particiones2 (x:xs) k = map ([x]:) (particiones2 xs (k-1)) ++ concatMap (inserta x) (particiones2 xs k) -- 3ª solución -- =========== particiones3 :: [a] -> Int -> [[[a]]] particiones3 xs k = matrizParticiones xs k ! (length xs, k) matrizParticiones :: [a] -> Int -> Array (Int,Int) [[[a]]] matrizParticiones xs k = q where q = array ((0,0),(n,k)) [((i,j), f i j) | i <- [0..n], j <- [0..k]] n = length xs v = listArray (1,n) xs f _ 0 = [] f 0 _ = [] f m 1 = [[take m xs]] f i j | i == j = [[[x] | x <- take i xs]] | otherwise = map ([v!i] :) (q!(i-1,j-1)) ++ concatMap (inserta (v!i)) (q!(i-1,j)) -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_particiones :: [Int] -> Positive Int -> Bool prop_particiones xs (Positive k) = all (iguales (particiones1 xs' k)) [particiones2 xs' k, particiones3 xs' k] where xs' = nub xs iguales xss yss = sort (map sort [map sort x | x <- xss]) == sort (map sort [map sort y | y <- yss]) -- La comprobación es -- λ> quickCheckWith (stdArgs {maxSize=10}) prop_particiones -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> length (particiones1 [1..12] 6) -- 1323652 -- (1.33 secs, 1,152,945,584 bytes) -- λ> length (particiones2 [1..12] 6) -- 1323652 -- (1.07 secs, 1,104,960,360 bytes) -- λ> length (particiones3 [1..12] 6) -- 1323652 -- (1.68 secs, 1,047,004,368 bytes) |
El código se encuentra en GitHub.
Un número semiprimo es un número natural es producto de dos números primos no necesariamente distintos. Por ejemplo, 26 es semiprimo (porque 26 = 2·13) y 49 también lo es (porque 49 = 7·7).
Definir la función
|
1 |
mayorSemiprimoMenor :: Integer -> Integer |
tal que (mayorSemiprimoMenor n) es el mayor semiprimo menor que n (suponiendo que n > 4). Por ejemplo,
|
1 2 3 4 |
mayorSemiprimoMenor 27 == 26 mayorSemiprimoMenor 50 == 49 mayorSemiprimoMenor 49 == 46 mayorSemiprimoMenor (10^15) == 999999999999998 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
import Data.Numbers.Primes (primeFactors, isPrime, primes) import Test.QuickCheck -- 1ª solución -- =========== mayorSemiprimoMenor1 :: Integer -> Integer mayorSemiprimoMenor1 n = head [x | x <- [n-1,n-2..2], semiPrimo x] semiPrimo :: Integer -> Bool semiPrimo n = not (null [x | x <- [n,n-1..2], primo x, n `mod` x == 0, primo (n `div` x)]) primo :: Integer -> Bool primo n = [x | x <- [1..n], n `mod` x == 0] == [1,n] -- 2ª solución -- =========== mayorSemiprimoMenor2 :: Integer -> Integer mayorSemiprimoMenor2 n = head [x | x <- [n-1,n-2..2], semiPrimo2 x] semiPrimo2 :: Integer -> Bool semiPrimo2 n = not (null [x | x <- [n-1,n-2..2], isPrime x, n `mod` x == 0, isPrime (n `div` x)]) -- 3ª solución -- =========== mayorSemiprimoMenor3 :: Integer -> Integer mayorSemiprimoMenor3 n = head [x | x <- [n-1,n-2..2], semiPrimo3 x] semiPrimo3 :: Integer -> Bool semiPrimo3 n = not (null [x | x <- reverse (takeWhile (<n) primes), n `mod` x == 0, isPrime (n `div` x)]) -- 4ª solución -- =========== mayorSemiprimoMenor4 :: Integer -> Integer mayorSemiprimoMenor4 n = head [ p | p <- [n-1,n-2..2] , (length . primeFactors) p == 2] -- 5ª solución -- =========== mayorSemiprimoMenor5 :: Integer -> Integer mayorSemiprimoMenor5 n | semiPrimo5 (n-1) = n-1 | otherwise = mayorSemiprimoMenor5 (n-1) semiPrimo5 :: Integer -> Bool semiPrimo5 x = length (primeFactors x) == 2 -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_mayorSemiprimoMenor :: Integer -> Property prop_mayorSemiprimoMenor n = n > 4 ==> all (== mayorSemiprimoMenor1 n) [mayorSemiprimoMenor2 n, mayorSemiprimoMenor3 n, mayorSemiprimoMenor4 n, mayorSemiprimoMenor5 n] -- La comprobación es -- λ> quickCheck prop_mayorSemiprimoMenor -- +++ OK, passed 100 tests; 353 discarded. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> mayorSemiprimoMenor1 5000 -- 4997 -- (1.92 secs, 945,507,880 bytes) -- λ> mayorSemiprimoMenor2 5000 -- 4997 -- (0.05 secs, 123,031,264 bytes) -- λ> mayorSemiprimoMenor3 5000 -- 4997 -- (0.01 secs, 5,865,120 bytes) -- λ> mayorSemiprimoMenor4 5000 -- 4997 -- (0.00 secs, 593,528 bytes) -- λ> mayorSemiprimoMenor5 5000 -- 4997 -- (0.00 secs, 593,200 bytes) -- -- λ> mayorSemiprimoMenor3 (3*10^6) -- 2999995 -- (2.34 secs, 6,713,620,000 bytes) -- λ> mayorSemiprimoMenor4 (2*10^6) -- 1999997 -- (0.01 secs, 728,936 bytes) -- λ> mayorSemiprimoMenor5 (2*10^6) -- 1999997 -- (0.01 secs, 728,608 bytes) |
El código se encuentra en GitHub.
Definir la función
|
1 |
interseccionParcial :: Ord a => Int -> [[a]] -> [a] |
tal que (interseccionParcial n xss) es la lista de los elementos que pertenecen al menos a n conjuntos de xss. Por ejemplo,
|
1 2 3 4 |
interseccionParcial 1 [[3,4],[4,5,9],[5,4,7]] == [3,4,5,9,7] interseccionParcial 2 [[3,4],[4,5,9],[5,4,7]] == [4,5] interseccionParcial 3 [[3,4],[4,5,9],[5,4,7]] == [4] interseccionParcial 4 [[3,4],[4,5,9],[5,4,7]] == [] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import Data.List (foldl', nub, union, sort) import Test.QuickCheck -- 1ª solución -- =========== interseccionParcial1 :: Ord a => Int -> [[a]] -> [a] interseccionParcial1 n xss = [x | x <- sort (elementos xss) , pertenecenAlMenos n xss x] elementos :: Ord a => [[a]] -> [a] elementos [] = [] elementos (xs:xss) = xs `union` elementos xss pertenecenAlMenos :: Ord a => Int -> [[a]] -> a -> Bool pertenecenAlMenos n xss x = length [xs | xs <- xss, x `elem` xs] >= n -- 2ª solución -- =========== interseccionParcial2 :: Ord a => Int -> [[a]] -> [a] interseccionParcial2 n xss = [x | x <- sort (elementos2 xss) , pertenecenAlMenos2 n xss x] elementos2 :: Ord a => [[a]] -> [a] elementos2 = foldl' union [] pertenecenAlMenos2 :: Ord a => Int -> [[a]] -> a -> Bool pertenecenAlMenos2 n xss x = length (filter (x `elem`) xss) >= n -- 3ª solución -- =========== interseccionParcial3 :: Ord a => Int -> [[a]] -> [a] interseccionParcial3 n xss = [x | x <- sort (nub (concat xss)) , length [xs | xs <- xss, x `elem` xs] >= n] -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_interseccionParcial :: Positive Int -> [[Int]] -> Bool prop_interseccionParcial (Positive n) xss = all (== interseccionParcial1 n yss) [interseccionParcial2 n yss, interseccionParcial3 n yss] where yss = map nub xss -- La comprobación es -- λ> quickCheck prop_interseccionParcial -- +++ OK, passed 100 tests. |
El código se encuentra en GitHub.
Definir las funciones
|
1 2 |
unionGeneral :: Eq a => [[a]] -> [a] interseccionGeneral :: Eq a => [[a]] -> [a] |
tales que
|
1 2 3 4 |
unionGeneral [] == [] unionGeneral [[1]] == [1] unionGeneral [[1],[1,2],[2,3]] == [1,2,3] unionGeneral ([[x] | x <- [1..9]]) == [1,2,3,4,5,6,7,8,9] |
|
1 2 3 4 5 |
interseccionGeneral [[1]] == [1] interseccionGeneral [[2],[1,2],[2,3]] == [2] interseccionGeneral [[2,7,5],[1,5,2],[5,2,3]] == [2,5] interseccionGeneral ([[x] | x <- [1..9]]) == [] interseccionGeneral (replicate (10^6) [1..5]) == [1,2,3,4,5] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
import Data.List (foldl', foldl1', intersect, nub, union) import Test.QuickCheck (NonEmptyList (NonEmpty), quickCheck) -- 1ª definición de unionGeneral -- ============================= unionGeneral1 :: Eq a => [[a]] -> [a] unionGeneral1 [] = [] unionGeneral1 (x:xs) = x `union` unionGeneral1 xs -- 2ª definición de unionGeneral -- ============================= unionGeneral2 :: Eq a => [[a]] -> [a] unionGeneral2 = foldr union [] -- 3ª definición de unionGeneral -- ============================= unionGeneral3 :: Eq a => [[a]] -> [a] unionGeneral3 = foldl' union [] -- Comprobación de equivalencia de unionGeneral -- ============================================ -- La propiedad es prop_unionGeneral :: [[Int]] -> Bool prop_unionGeneral xss = all (== unionGeneral1 xss') [unionGeneral2 xss', unionGeneral3 xss'] where xss' = nub (map nub xss) -- La comprobación es -- λ> quickCheck prop_unionGeneral -- +++ OK, passed 100 tests. -- (0.85 secs, 1,017,807,600 bytes) -- Comparación de eficiencia de unionGeneral -- ========================================= -- La comparación es -- λ> length (unionGeneral1 ([[x] | x <- [1..10^3]])) -- 1000 -- (1.56 secs, 107,478,456 bytes) -- λ> length (unionGeneral2 ([[x] | x <- [1..10^3]])) -- 1000 -- (1.50 secs, 107,406,560 bytes) -- λ> length (unionGeneral3 ([[x] | x <- [1..10^3]])) -- 1000 -- (0.07 secs, 92,874,024 bytes) -- 1ª definición de interseccionGeneral -- ==================================== interseccionGeneral1 :: Eq a => [[a]] -> [a] interseccionGeneral1 [x] = x interseccionGeneral1 (x:xs) = x `intersect` interseccionGeneral1 xs -- 2ª definición de interseccionGeneral -- ==================================== interseccionGeneral2 :: Eq a => [[a]] -> [a] interseccionGeneral2 = foldr1 intersect -- 3ª definición de interseccionGeneral -- ==================================== interseccionGeneral3 :: Eq a => [[a]] -> [a] interseccionGeneral3 = foldl1' intersect -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_interseccionGeneral :: NonEmptyList [Int] -> Bool prop_interseccionGeneral (NonEmpty xss) = all (== interseccionGeneral1 xss') [interseccionGeneral2 xss', interseccionGeneral3 xss'] where xss' = nub (map nub xss) -- La comprobación es -- λ> quickCheck prop_interseccionGeneral -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> interseccionGeneral1 (replicate (10^6) [1..5]) -- [1,2,3,4,5] -- (2.02 secs, 1,173,618,400 bytes) -- λ> interseccionGeneral2 (replicate (10^6) [1..5]) -- [1,2,3,4,5] -- (1.83 secs, 1,092,120,224 bytes) -- λ> interseccionGeneral3 (replicate (10^6) [1..5]) -- [1,2,3,4,5] -- (1.33 secs, 985,896,136 bytes) |
El código se encuentra en GitHub.
Definir la función
|
1 |
cerosDelFactorial :: Integer -> Integer |
tal que (cerosDelFactorial n) es el número de ceros en que termina el factorial de n. Por ejemplo,
|
1 2 3 |
cerosDelFactorial 24 == 4 cerosDelFactorial 25 == 6 length (show (cerosDelFactorial (10^70000))) == 70000 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import Data.List (genericLength) import Test.QuickCheck (Positive (Positive), quickCheck) -- 1ª solución -- =========== cerosDelFactorial1 :: Integer -> Integer cerosDelFactorial1 n = ceros (factorial n) -- (factorial n) es el factorial n. Por ejemplo, -- factorial 3 == 6 factorial :: Integer -> Integer factorial n = product [1..n] -- (ceros n) es el número de ceros en los que termina el número n. Por -- ejemplo, -- ceros 320000 == 4 ceros :: Integer -> Integer ceros n | rem n 10 /= 0 = 0 | otherwise = 1 + ceros (div n 10) -- 2ª solución -- =========== cerosDelFactorial2 :: Integer -> Integer cerosDelFactorial2 = ceros2 . factorial ceros2 :: Integer -> Integer ceros2 n = genericLength (takeWhile (=='0') (reverse (show n))) -- 3ª solución -- ============= cerosDelFactorial3 :: Integer -> Integer cerosDelFactorial3 n | n < 5 = 0 | otherwise = m + cerosDelFactorial3 m where m = n `div` 5 -- Comprobación de equivalencia -- ============================ -- La propiedad es prop_cerosDelFactorial :: Positive Integer -> Bool prop_cerosDelFactorial (Positive n) = all (== cerosDelFactorial1 n) [cerosDelFactorial2 n, cerosDelFactorial3 n] -- La comprobación es -- λ> quickCheck prop_cerosDelFactorial -- +++ OK, passed 100 tests. -- Comparación de eficiencia -- ========================= -- La comparación es -- λ> cerosDelFactorial1 (4*10^4) -- 9998 -- (1.93 secs, 2,296,317,904 bytes) -- λ> cerosDelFactorial2 (4*10^4) -- 9998 -- (1.57 secs, 1,636,242,040 bytes) -- λ> cerosDelFactorial3 (4*10^4) -- 9998 -- (0.02 secs, 527,584 bytes) |
El código se encuentra en GitHub.