Conjetura de Goldbach
Una forma de la conjetura de Golbach afirma que todo entero mayor que 1 se puede escribir como la suma de uno, dos o tres números primos.
Si se define el índice de Goldbach de n > 1 como la mínima cantidad de primos necesarios para que su suma sea n, entonces la conjetura de Goldbach afirma que todos los índices de Goldbach de los enteros mayores que 1 son menores que 4.
Definir las siguientes funciones
|
1 2 |
indiceGoldbach :: Int -> Int graficaGoldbach :: Int -> IO () |
tales que
- (indiceGoldbach n) es el índice de Goldbach de n. Por ejemplo,
|
1 2 3 4 5 |
indiceGoldbach 2 == 1 indiceGoldbach 4 == 2 indiceGoldbach 27 == 3 sum (map indiceGoldbach [2..5000]) == 10619 maximum (map indiceGoldbach [2..5000]) == 3 |
- (graficaGoldbach n) dibuja la gráfica de los índices de Goldbach de los números entre 2 y n. Por ejemplo, (graficaGoldbach 150) dibuja


Comprobar con QuickCheck la conjetura de Goldbach anterior.
Soluciones
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
import Data.Array import Data.Numbers.Primes import Graphics.Gnuplot.Simple import Test.QuickCheck -- 1ª definición -- ============= indiceGoldbach :: Int -> Int indiceGoldbach n = minimum (map length (particiones n)) particiones :: Int -> [[Int]] particiones n = v ! n where v = array (0,n) [(i,f i) | i <- [0..n]] where f 0 = [[]] f m = [x:y | x <- xs, y <- v ! (m-x), [x] >= take 1 y] where xs = reverse (takeWhile (<= m) primes) -- 2ª definición -- ============= indiceGoldbach2 :: Int -> Int indiceGoldbach2 x = head [n | n <- [1..], esSumaDe x n] -- (esSumaDe x n) se verifica si x se puede escribir como la suma de n -- primos. Por ejemplo, -- esSumaDe 2 1 == True -- esSumaDe 4 1 == False -- esSumaDe 4 2 == True -- esSumaDe 27 2 == False -- esSumaDe 27 3 == True esSumaDe :: Int -> Int -> Bool esSumaDe x 1 = isPrime x esSumaDe x n = or [esSumaDe (x-p) (n-1) | p <- takeWhile (<= x) primes] -- 3ª definición -- ============= indiceGoldbach3 :: Int -> Int indiceGoldbach3 x = head [n | n <- [1..], esSumaDe3 x n] esSumaDe3 :: Int -> Int -> Bool esSumaDe3 x n = a ! (x,n) where a = array ((2,1),(x,9)) [((i,j),f i j) | i <- [2..x], j <- [1..9]] f i 1 = isPrime i f i j = or [a!(i-k,j-1) | k <- takeWhile (<= i) primes] -- 4ª definición -- ============= indiceGoldbach4 :: Int -> Int indiceGoldbach4 n = v ! n where v = array (2,n) [(i,f i) | i <- [2..n]] f i | isPrime i = 1 | otherwise = 1 + minimum [v!(i-p) | p <- takeWhile (< (i-1)) primes] -- Comparación de eficiencia -- ========================= -- λ> sum (map indiceGoldbach [2..80]) -- 142 -- (2.66 secs, 1,194,330,496 bytes) -- λ> sum (map indiceGoldbach2 [2..80]) -- 142 -- (0.01 secs, 1,689,944 bytes) -- λ> sum (map indiceGoldbach3 [2..80]) -- 142 -- (0.03 secs, 27,319,296 bytes) -- λ> sum (map indiceGoldbach4 [2..80]) -- 142 -- (0.03 secs, 47,823,656 bytes) -- -- λ> sum (map indiceGoldbach2 [2..1000]) -- 2030 -- (0.10 secs, 200,140,264 bytes) -- λ> sum (map indiceGoldbach3 [2..1000]) -- 2030 -- (3.10 secs, 4,687,467,664 bytes) -- Gráfica -- ======= graficaGoldbach :: Int -> IO () graficaGoldbach n = plotList [ Key Nothing , XRange (2,fromIntegral n) , PNG ("Conjetura_de_Goldbach_" ++ show n ++ ".png") ] [indiceGoldbach2 k | k <- [2..n]] -- Comprobación de la conjetura de Goldbach -- ======================================== -- La propiedad es prop_Goldbach :: Int -> Property prop_Goldbach x = x >= 2 ==> indiceGoldbach2 x < 4 -- La comprobación es -- λ> quickCheck prop_Goldbach -- +++ OK, passed 100 tests. |
Otras soluciones
- Se pueden escribir otras soluciones en los comentarios.
- El código se debe escribir entre una línea con <pre lang="haskell"> y otra con </pre>
Pensamiento
«La diferencia entre los matemáticos y los físicos es que después de que los físicos prueban un gran resultado piensan que es fantástico, pero después de que los matemáticos prueban un gran resultado piensan que es trivial.»
 , cifra que luego de algunos refinamientos se redujo a
, cifra que luego de algunos refinamientos se redujo a 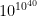 .
.